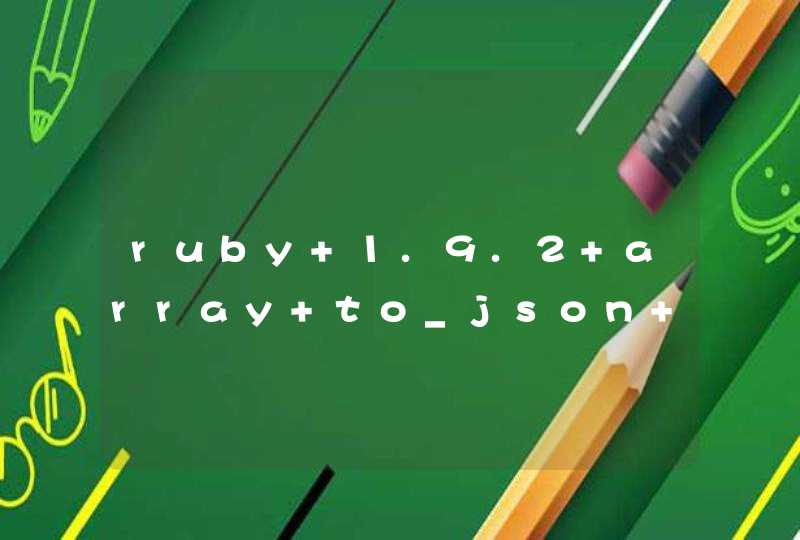import pandas as pd
import xlsxwriter
if __name__ == "__main__":
file_name = r'C:\Users\Administrator\Desktop\test.xlsx'
""" 读取,切割成数组 """
context = pd.read_excel(file_name)
num = context['序号'][0]
value = context['名称'][0]
new_num = num.split('\n')
new_value = value.split('\n')
""" 写入数据 """
workbook = xlsxwriter.Workbook(file_name)
# 创建工作表
worksheet = workbook.add_worksheet('sheet1')
# 写单元格
worksheet.write(0, 0, '序号')
worksheet.write(0, 1, '名称')
# 写列,其中列需要大写
worksheet.write_column('A2', new_num)
worksheet.write_column('B2', new_value)
# 关闭工作簿
workbook.close()
###顺便给一下你学习的链接吧,这个其实就是个简单的读写文件的应用而已,网页链接
Python中split()函数,通常用于将字符串切片并转换为列表。
split():语法:
拆分字符串。通过制定分隔符将字符串进行切片,并返回分割后的字符串列表[list]
参数:str:分隔符,默认为空格,但不能为空("")
num: 表示分割次数。如果指定num,则分割成n+1个子字符串,并可将每个字符串赋给新的变量
line.strip().split(’,’)
strip()表示删除掉数据中的换行符,split(‘,’)则是数据中遇到‘,’ 就隔开。
from __future__ import with_statement # for Python25txt_file = 'txt.txt'
i = 0
lines = []
with open(txt_file, 'rU') as f:
for line in f:
if line.isspace():
print '%d:' % i
print ''.join(lines)
lines = []
i += 1
else:
lines.append(line)
if lines != []:
print '%d:' % i
print ''.join(lines)