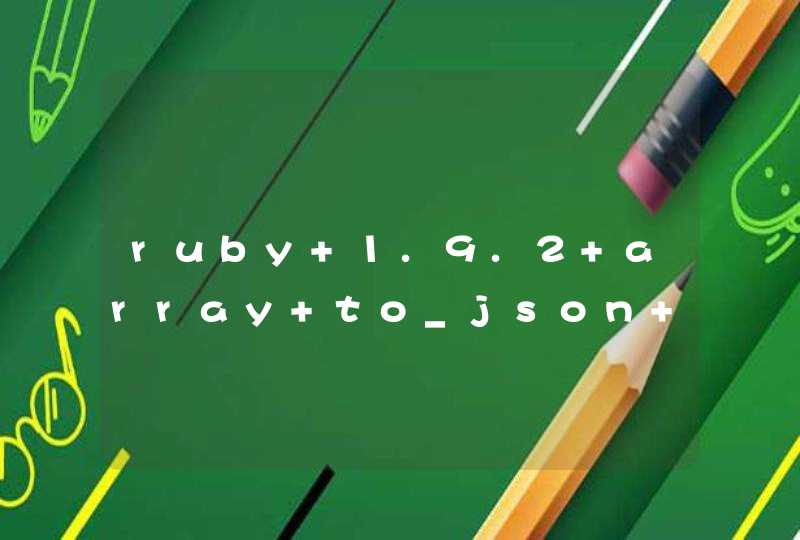两种可能结果的离散随机变量概率分布 ,失败是0,成功是1,p是成功的概率。
dbinorm() :提供任何有效x的概率质量函数
pbinom() :提供累积概率分布,求结果成功q次及q次以下的累积概率,给定分位数值q,输出累积概率p
qbinom() :累积概率分布的逆( pbinom() 的逆),给定累积概率p,输出分位数值q
rbinom() :产生n个服从二项分布的随机数
3. dpois() , ppois() , qpois() , rpois()
dt() , pt() , qt() , rt()
卡方拟合优度检验,用于衡量观测频数与期望频数之间的差异
一般地,假设总体分r类 ,分布假设检验问题
在原假设下, 期望频数 :
假设从总体中随机抽取n个样本,并记 为样本中分到类中的个数,称为 观测频数 。
K.Pearson在原假设 成立下:
因此,在显著性水平 下,拒绝域为
p-value = 0.9254>0.05,则不应拒绝原假设,孟德尔的结论是成立的。
同理,可以先计算出
某美发店上半年各月顾客数量如下,请问该店各月顾客数是否为均匀分布?
我们用R语言来模拟一下实际操作
R语言实验结果与示例完全相同。
R语言中一组数据服从威布尔分布。首先可以利用fitdistr函数求得weibull分布的形状参数和尺寸参数,假设数据为x:library(MASS) #fitdistr需要利用MASS包fitdistr(x, densfun = "weibull",lower=0)得到形状参数shape与尺度参数scale
然后利用ks.test进行检验:ks.test(jitter(x),"pweibull",shape,scale)
上边的jitter用来做小扰动,因为如果x中有重复数据的话ks.test会报错,如果x中没有重复数据则不需要jitter。shape是得到的形状参数,scale是得到的尺度参数。
ks.test得到两个结果,一个是D,越小越好,一个是p-value,这个值要大于0.05