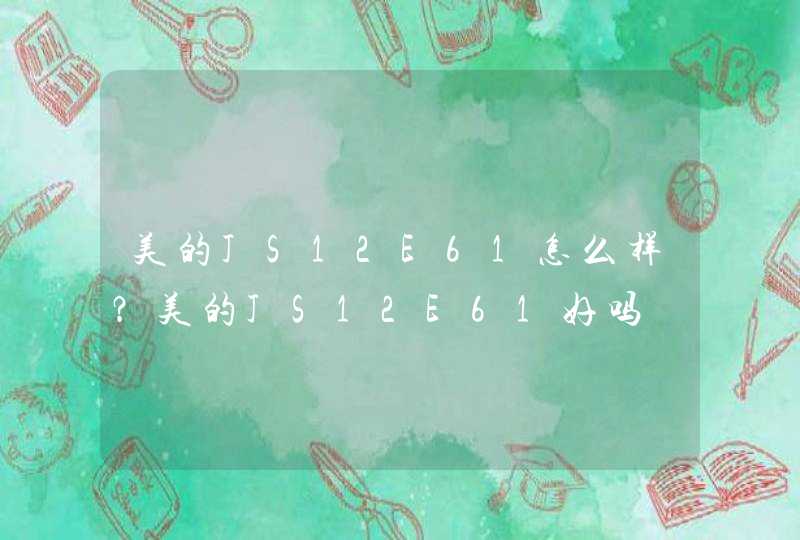前面我给大家详细介绍过
☞GO简介及GO富集结果解读
☞四种GO富集柱形图、气泡图解读
☞GO富集分析四种风格展示结果—柱形图,气泡图
☞KEGG富集分析—柱形图,气泡图,通路图
☞ DAVID GO和KEGG富集分析及结果可视化
也用视频给大家介绍过
☞ GO和KEGG富集分析视频讲解
最近有粉丝反映说,利用clusterProfiler这个包绘制GO富集分析气泡图和柱形图的时候,发现GO条目的名字都重叠在一起了。
气泡图
柱形图
这个图别说美观了,简直不忍直视。经过我的认真研究,发现跟R版本有关。前面我给大家展示的基本都是R 3.6.3做出来的图。很多粉丝可能用的都是最新版本的R 4.1.2。
我们知道R的版本在不停的更新,相应的R包也在不停的更新。我把绘制气泡图和柱形图相关的函数拿出来认真的研究了一下,终于发现的症结所在。
dotplot这个函数,多了个 label_format 参数
我们来看看这个参数究竟是干什么用的,看看参数说明
label_format :
a numeric value sets wrap length, alternatively a custom function to format axis labels. by default wraps names longer that 30 characters
原来这个参数默认值是30,当标签的长度大于30个字符就会被折叠,用多行来展示。既然问题找到了,我们就来调节一下这个参数,把他设置成100,让我们的标签可以一行展示。
是不是还是原来的配方,还是熟悉的味道
同样的柱形图,我们也能让他恢复原来的容貌。
关于如何使用R做GO和KEGG富集分析,可参考下文
GO和KEGG富集分析视频讲解
模型拟合对于人口模型可以采用Logistic增长函数形式,它考虑了初期的指数增长以及总资源的限制。其函数形式如下。
首先载入car包以便读取数据,然后使用nls函数进行建模,其中theta1、theta2、theta3表示三个待估计参数,start设置了参数初始值,设定trace为真以显示迭代过程。nls函数默认采用Gauss-Newton方法寻找极值,迭代过程中第一列为RSS值,后面三列是各参数估计值。然后用summary返回回归结果。
library(car)
pop.mod1 <- nls(population ~ theta1/(1+exp(-(theta2+theta3*year))),start=list(theta1 = 400, theta2 = -49, theta3 = 0.025), data=USPop, trace=T)
summary(pop.mod)
在上面的回归过程中我们直接指定参数初始值,另一种方法是采用搜索策略,首先确定参数取值范围,然后利用nls2包的暴力方法来得到最优参数。但这种方法相当费时。
还有一种更为简便的方法就是采用内置自启动模型(self-starting Models),此时我们只需要指定函数形式,而不需要指定参数初始值。本例的logistic函数所对应的selfstarting函数名为SSlogis
pop.mod2 <- nls(population ~ SSlogis(year,phi1,phi2,phi3),data=USPop)
二、判断拟合效果
非线性回归模型建立后需要判断拟合效果,因为有时候参数最优化过程会捕捉到局部极值点而非全局极值点。最直观的方法是在原始数据点上绘制拟合曲线。
library(ggplot2)
p <- ggplot(USPop,aes(year, population))