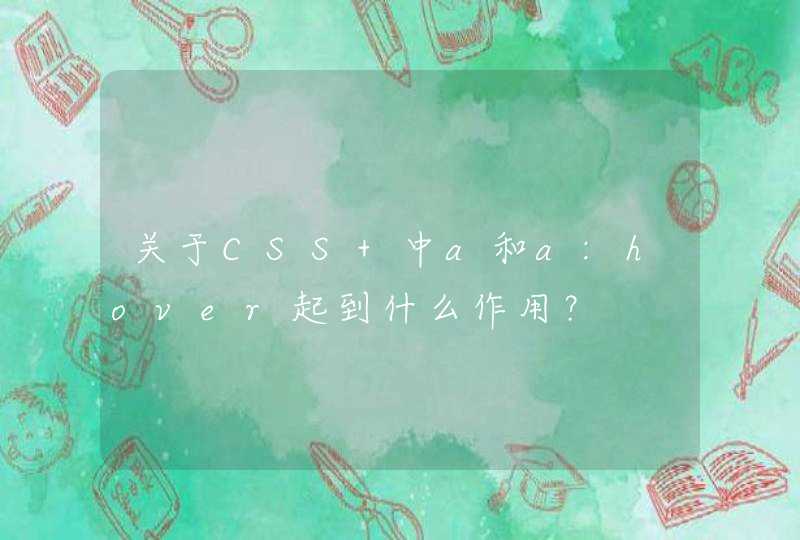function sum(i)
{
if (i == 1) return 1
return i + sum(i - 1)
}
显然,这是一个递归函数,函数自己调用自己。
那么每个调用,都必须保存一个i的变量。
此时就要用堆栈。堆栈的栈顶始终保持着函数的局部变量。当函数返回,则往回收缩,这多方便。
而堆呢?适合全局的、一般的存储。
堆和栈的区别:
一.堆栈空间分配区别:
1.栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈;
2.堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
二.堆栈缓存方式区别:
1.栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放;
2.堆是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
三.堆栈数据结构区别:
堆(数据结构):堆可以被看成是一棵树,如:堆排序;
栈(数据结构):一种先进后出的数据结构。
扩展资料:
堆支持以下的基本:
1.build:建立一个空堆;
2.insert:向堆中插入一个新元素;
3.update:将新元素提升使其符合堆的性质;
4.get:获取当前堆顶元素的值;
5.delete:删除堆顶元素;
6.heapify:使删除堆顶元素的堆再次成为堆。
某些堆实现还支持其他的一些操作,如斐波那契堆支持检查一个堆中是否存在某个元素。
栈的基本算法
1.进栈(PUSH)算法
①若TOP≥n时,则给出溢出信息,作出错处理(进栈前首先检查栈是否已满,满则溢出;不满则作②);
②置TOP=TOP+1(栈指针加1,指向进栈地址);
③S(TOP)=X,结束(X为新进栈的元素);
2.退栈(POP)算法
①若TOP≤0,则给出下溢信息,作出错处理(退栈前先检查是否已为空栈, 空则下溢;不空则作②);
②X=S(TOP),(退栈后的元素赋给X):
③TOP=TOP-1,结束(栈指针减1,指向栈顶)。
参考资料:百度百科:堆
百度百科:栈