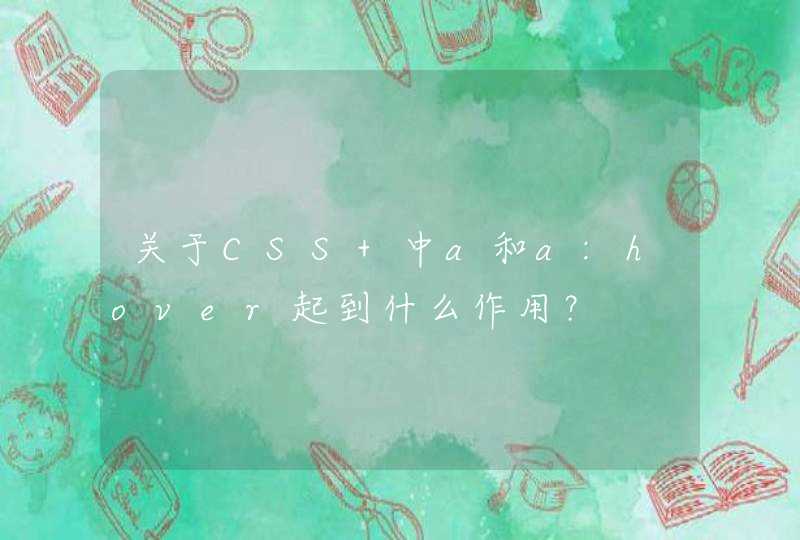from __future__ import print_function使能print函数形式)
其实,在python2.X手册中对print语句描述说:(python2.7.2官方帮助文档)
一个空格会被自动打印在每个对象前,
除非:(1)还没有输出写到标准输出中
(2)当最后一个写到标准输出的是一个除了空格‘ ’的空白字符
(3)当最后写到标准输出的不是一个print语句。
所以在apple、banana等每个字符前都有一个空格。(apple的a前也有空格呢!)
一个好的解决办法是使用python3.X中的print函数。
通过在文件前面加上:
from __future__ import print_function
就可以使用print的函数形式了。
print函数的语法:
print([object, ...][, sep=' '][, end='\n'][, file=sys.stdout])
默认下,若没有指定sep,则使用空格。没指定end,则使用换行符。没指定输出文件则输出到标准输出。
例如:print('hello','world',sep='-',end='#')输出:
hello-world#
所以,你的程序可改为:
from __future__ import print_function
list = ["apple", "banana", "grape", "orange"]
for x in range(len(list)):
print('list[%d]:'%x,end='')
for y in range(len(list[x])):
print(list[x][y],sep='',end='')
print('')
至于: 'list[%d]:'%x 这里的百分号,是一个对字符串的操作符。百分号使得百分号前面的字符串中
的%d被百分号后的x的值替换掉。
Python的for...in 循环有三种常见用法:
第一,按长度遍历 :
若不需要索引号index,可以直接用"for obj in obj-list"语句遍历
第二,若既需要索引,又需要成员值,可以用enumerate()函数
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串),同时输出数据和数据下标,常用于for-in循环。
第三,不关心索引,只希望同时遍历多个列表,可以用zip函数。
zip函数将多个列表作为输入,在每次迭代的时候,将每个列表的当前成员组合成一个元组输出。