












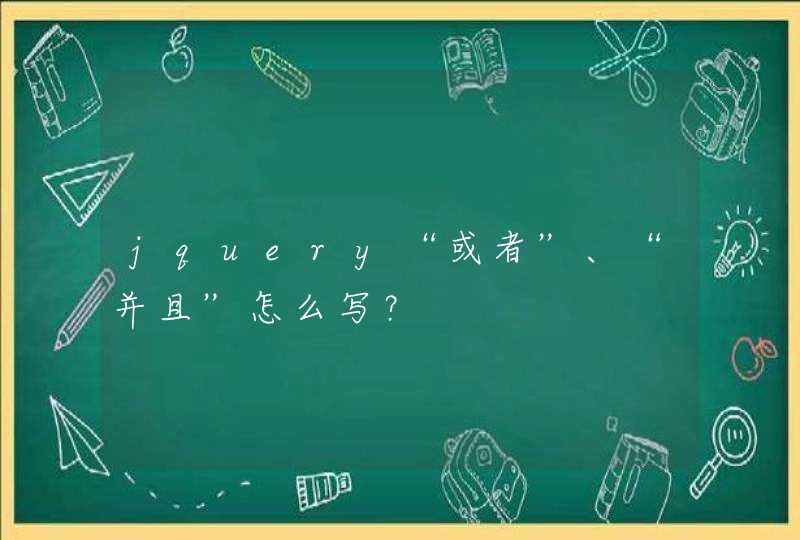



























字符串的最大长度与js中能表达的【最大安全整数】有关系,这是为什么呢
utf-16相关:
符号位1 指数为11 位位尾数位52 (1+11+52=64)
那应该是2^52-1 才对,但小数点前保留一位规格化后始终是1.***这个不需要存,所以这样就成了2^53-1
我理解是:只要转码后的二进制总长度不超出2^53-1就行,但是不一样的编码方式转码后的二进制长度不相同,所以字符串最大字符长度受字符串编码方式影响
负数求二进制
例:-14
原码->反码->补码
原码0000 1110 (14= 2^3 + 2^2 + 2^1)
反码 1111 0001(按位取反)
补码 1111 0010(反码加一)
小数二进制
例:1.5的二进制1.1,二进制1.1反推回去:1 * 2^0 + 1 * 2^(-1)=1.5
JS字符串的长度受到下标限制。理论最大长度是2^53-1(即js中可表达的最大安全整数)。2^53是多大呢?大约9PB。根据统计,中国2014年所有出版物(不计复本)不到2000亿字,也就是400GB而已。按此推算,不要说存一个txt了,中国自有甲骨文以来所有的书、各类出版物字数加在一起估计也不可能超过100TB,也就是0.1PB。当然啦,实际引擎是不可能允许分配那么大的字符串的,你的电脑也没那么大存储不是。V8的heap上限只有2GB不到,允许分配的单个字符串大小上限更只有大约是512MB不到。JS字符串是UTF16编码保存,所以也就是2.68亿个字符。FF大约也是这个数字。根据最长的网络小说是哪部,目前最长的网络小说大概2000万字。所以还是绰绰有余的。《道藏》大约7000万字,《大藏经》大约1亿字,也是存得下的。不过《永乐大典》有3.7亿字,《四库全书》有8亿字,V8/FF的一个字符串就存不下喽。然而IE11貌似可以存4GB的字符串,即21亿字。其实限制是在服务器资源、网速和存储。你文本还没读完,值还没赋完,内存不够了。内存够了,几百m几个G的变量,搞得页面请求超时了,访客没耐心关掉了,或者浏览器内存崩溃了。取一次吗?还是经常要用,要持久化不,数据库肯定存不下,文件存吧〔占硬盘,存不了几个〕,又每次要io读。你干嘛不搞几百字的简介,配个图,附上文件的下载地址〔放网盘,2T内免费〕不是很好吗。
//GBK字符集实际长度计算function
getStrLeng(str){
var
realLength
=
0
var
len
=
str.length
var
charCode
=
-1
for(var
i
=
0
i
<
len
i++){
charCode
=
str.charCodeAt(i)
if
(charCode
>=
0
&&
charCode
<=
128)
{
realLength
+=
1
}else{
//
如果是中文则长度加2
realLength
+=
2
}
}
return
realLength}
//
UTF8字符集实际长度计算function
getStrLeng(str){
var
realLength
=
0
var
len
=
str.length
var
charCode
=
-1
for(var
i
=
0
i
<
len
i++){
charCode
=
str.charCodeAt(i)
if
(charCode
>=
0
&&
charCode
<=
128)
{
realLength
+=
1
}else{
//
如果是中文则长度加3
realLength
+=
3
}
}
return
realLength}
在JS中字符串的长度不分中英文字符,
每一个字符都算一个长度,这跟PHP里的strlen()函数就不太一样。PHP里的strlen()函数根据字符集把GBK的中文每个2累加,把UTF-8的中文字符每个按3累加。主要是为了匹配数据库的长度范围内,比如GBK的数据库某字段是varchar(10),那么就相当于5个汉字长度,一个汉字等于两个字母长度。如果是UTF8的数据库则是每个汉字长度为3。




























