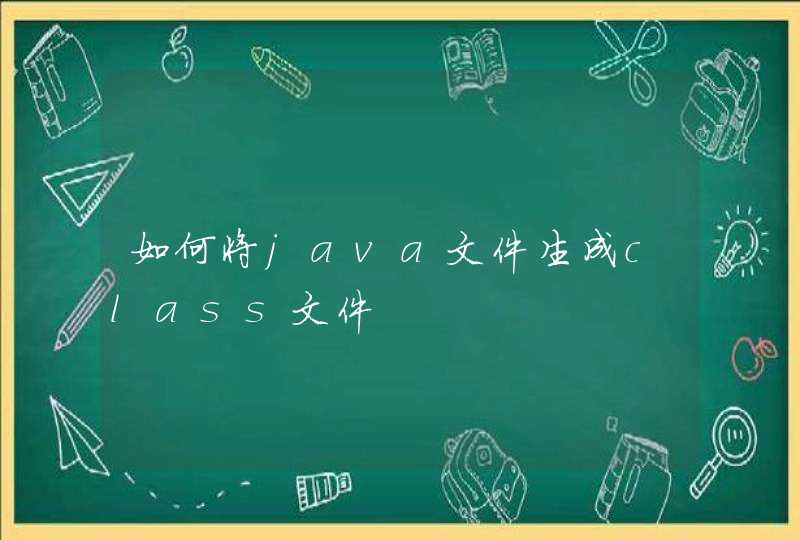一次重启服务器后,supervisor接管的python脚本中的函数 open() 和 print() 都会报下面的编码错误:
UnicodeEncodeError: 'ascii' codec can't encode
使用的是python3,按理说编码都会默认utf-8,而且本地运行的python脚本并没有这个问题。
经大佬指点,增加环境变量 export LC_ALL="en_US.UTF-8" 后,再重启supervisor,问题解决
下面是复制的: https://www.cnblogs.com/badboy200800/p/11215981.html
Locale是一个软件在运行时的语言环境,。是根据计算机用户所使用的语言,所在国家或者地区,以及当地的文化传统所定义的。它包括语言(Language), 地域 (Territory) 和字符集(Codeset)。
一个locale的书写格式为: 语言[ 地域[.字符集]]。完全的locale表达方式是 [语言[ 地域][.字符集] [@修正值]。例如:
zh_CN.GB2312 => 中文_中华人民共和国+国标2312字符集。
(1)locale把按照所涉及到的文化传统的各个方面分成12个大类
(2)查看标准字符集列表
常用字符集:en_US.utf8、zh_CN.gb2312、zh_CN.gbk、zh_CN.utf8等
3.Locale的设定
LC_ALL和LANG优先级的关系:LC_ALL >LC_* >LANG
(1)如果需要一个纯中文的系统的话,设定LC_ALL= zh_CN.XXXX即可。或者设定LANG=zh_CN.XXXX也可以,但是LC_ 不要有任何特殊设定才可以(因为LC_ 优先级高)。
(2)如果需要个性化的环境,例如只想要一个可以输入中文的环境,而保持菜单、标题,系统信息等等为英文界面,那么只需要设定LANG=en_US.XXXX,然后 LC_CTYPE=zh_CN.XXXX就可以了。
(3)假如什么也不做的话,也就是LC_ALL,LANG和LC_*均不指定特定值的话,系统将采用POSIX作为lcoale,也就是C locale。
4.查看与设定字符集实践
(1)查看当前系统字符集三种方式(LC_ALL、LC_CTYPE和LANG),以查看LANG为例:
(2)更改系统字符集
备注:直接执行上述命令,可以临时修改系统字符集。如果写入环境变量可以永久改变字符集。
(3)取消当前系统字符集(设定为空)
备注:直接执行上述命令,可以临时修改系统字符集。如果写入环境变量可以永久改变字符集。
在python3中系统默认编码是unicode,读取文件经常会编码错误导致报错。
首先先确认要读取文件的编码,可这样操作:
记事本打开文本文件,点击“文件”-“另存为”查看编码:
如图显示编码就是当前的文件编码,这里是“utf-8”。
2. 要想用指定编码打开,使用codecs模块
安装模块pip命令:
pip install codecs3. 使用codecs模块,例如读取test文件内容并打印:
import codecsf=codecs.open(r"test.txt","r","gbk")
print(f.read())
f.close()
(示例的文件是ANSI所以使用GBK读取)
以上就可以正确读取想要的文件了
Python代码报错是编码错误,解决方法如下:
1、当程序文件中,存在中文字符时候,文件未声明编码格式就会出现报错信息。
2、根据错误提示,我们在python官网得到如下帮助信息:如果没有其他编码提示,Python将默认为ASCII作为标准编码。
3、所以,按照帮助文档的提示以及例子,我们在Python文件中加入一个编码声明。
4、保存之后,再次运行,运行成功。
5、虽然声明了编码,但是以上写法运行之后仍然报错,是因为编码声明的位置不正确,声明编码必须在文件的第1行或者第2行,且第1行不能包含中文字符。
6、修改之后就可以成功运行了。
注意事项:
有时候已经声明了编码,但是还会报错,是因为声明编码的位置不正确。