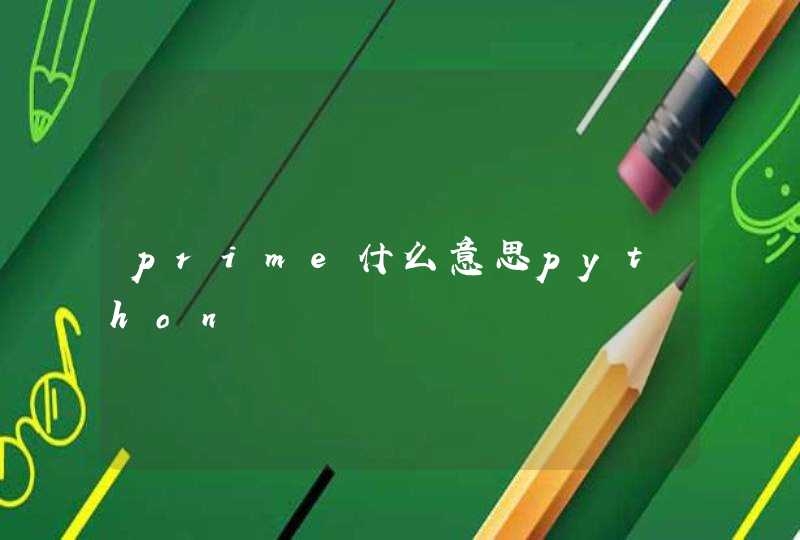%>%是管道符的意思,把左边的输出(不包括 <- 之前的)当成右边的输入。
都可以shift + alt + 上下 :快速复制粘贴
alt + 上下 :移动行
ctrl + alt + 上下 :多重光标
首先选中要注释掉的行,然后按Ctrl+shift+C ,这样就注释掉了。
sessionInfo()
.libPaths()
一篇关于包的博客
library(installr)
updateR()
COS中文论坛 统计之都旗下的论坛网站(d.cosx.org),它和其主站(cosx.org)一 起,是一个致力于推广与应用统计学知识的网站和社区。
1 help("t.test")
2 ?t.test
3 help.search("t.test")
4 apropos("t.test")
5 RGui>Help>Html help
6 查看R包pdf手册
getwd() 显示工作目录
setwd() 设定工作目录
list.files() 列出目录或文件夹下的文件
demo( ) 显示R的基本程序包
example( ) 显示在线帮助的例子
example(barplot)
可以把若干行命令保存在一个文本文件(比如Eg3.R)中,然 后用source函数来运行整个文件: source("E:/R demo/Chapter1-Eg3.R")
sum, mean, var, sd, min, max, range, median, IQR(四分位间距)等为统计量, sort,order,rank与排序有关, 其它还有ave,fivenum,mad,quantile, stem等
-1:1/0 当中/是优先级靠后的操作。相当于c(-1,0,1)/0
names(df) <- c("male", "female", "unknown")
对于矩阵,我们可以使用属性rownames和colnames来访问行名和列名。
我们也可以先定义矩阵x然后再为dimnames(x)赋值:
数值型数据 :1.2345e30
复数常量就用3.5-2.1i
缺失值:NA(Not Available)
是否含有缺失值:
NaN表示不确定的数
• NaN属于NA的一种
• NA不是NaN
注意下面例子的比较 :
assign("x1", c(1, 2))
sort(x)返回x的元素从小到大排序的结果向量。
x=c(2,10,6,8,4,5)sort(x) [1] 2 4 5 6 8 10 order(x)返回使得x从小到大排列的元素下标向量(x[order(x)]等效于sort(x))。
此外numeric(n)可以产生一个长度为n的零向量(numeric(n)是一个 很好用的外部存储器)
paste函数用来把它的自变量连成一个字符串,中间用空格分开
Re( )计算实部,Im( )计算虚部, Mod( ) 计算复数模,Arg( )计算复数幅角。
v为一个向量,取值在-length(x)到-1之间,表示扣除相应 位置的元素。例如:
可以用x[]的写法:
R的对象有两个基本的属性:类型属性(mode)和长度属性(length)。
长度为零的向量 numeric( ) 或者 numeric(0) character( ) 或者 character(0)
数组(array): 带多个下标的类型相同的元素的集合,
函数matrix():用于构造二维数组,即矩阵
函数factor( )用来把一个向量编码成为一个因子。
可以自行指定各离散取值水平(levels),不指定时由x的不同值来求得。
• labels可以用来指定各水平的标签,不指定时用各离散取值的对应字符串。
• exclude参数用来指定要转换为缺失值(NA)的元素值集合。
• ordered取真值时表示因子水平(Levels)是有次序的
因子可以用来作为另外的同长度变量的分类变量,使用tapply() 函数可以完成分类统计
nchar()这个函数简单,统计向量中每个元素的字符个数
tolower()和toupper()可以进行大小写字母的转换
chartr()把字符串里的元素,按要求进行转换
拆分字符串用strsplit()函数,strsplit得到的结果是列表,后面的处理要调用列表
其任何一个语句都可以看成是一个表达式。
表达式之间以分号分隔或用换行分隔。
表达式可以续行,只要前一行不是完整表达式,则下一行为上一行的继续。
线性回归模型:
lm()函数的返回值叫做模型拟合结果对象,本质上是一个列表, 有model 、coefficients、residuals等成员。lm()的结果显示十分 简单,为了获得更多的拟合信息,可以使用对lm类对象有特 殊操作的通用函数,这些函数包括:
add1 coef effects kappa predict residuals alias deviance family labels print summary anova drop1 formula plot proj
加号+或 者减号-,表示在模型中加入一项或去掉一项,第一项前面如果是加号可以 省略
在非交互运行(程序)中应使用print()来输出。
• digits参数指定每个数输出的有效数字位数;
• quote 参数指定字符串输出时是否带两边的撇号;
• print.gap参数指定矩阵或数组输出时列之间的间距
也用来输出,但它可以把多个参数连接起来再输出(具有paste() 的功能)。例如:
读取文件:
strsplit()得到的结果是 列表。
grep() 和 grepl()
sub()和gsub()
但严格地说R语言 没有字符串替换的函数,因为R语言不管什么操作对参数都是传值不传址,区别如下:
用substr()和substring() 可以通过位置进行字符串拆分或提取,两者的参数设置基本相同:
strtrim() 函数可以用于将字符串修剪到特定的显示宽度通过位置进 行字符串拆分或提取:
由于日期内部是用double存储的天数,所以是可以相减的。
weekdays ( )取日期对象所处的周几;
months ( )取日期对象的月份;
quarters ( )取日期对象的季度;
其任何一个语句都可以看成是一个表达式。
表达式之间以分号分隔或用换行分隔。
表达式可以续行,只要前一行不是完整表达式,则下一行为上一行的继续。
quantile(x, probs=seq(0,1,0.25), na.rm=FALSE, names=TRUE, type=7, …)
probs给出相应的百分位数,默认值是0,0.25,0.5,0.75,1;na.rm是处 理缺失数据的,na.rm=TRUE时,NA和NaN将从数据中移走,向量取值中 若有NA或NaN,要添加这一参数,否则会出错;names若为TRUE,返回 值当中有names这个属性"type是取值1-9的整数,选择了九种分位数算法 (具体算法见帮助文件)中的一种。
数据的分布主要考察分布函数(p), 密度函数(d), 分位数函数(q)及产生随机数(r)
以正态分布为例:
hist(x, breaks="Sturges", freq=NULL, probability=!freq,… )
break规定了直方图的组距(必须覆盖数据的范围);freq是逻辑变量,TRUE是频率直方图, FALSE是密度直方图;probability和freq相反,TRUE是密度直方图,FALSE是频率直方图
其形式为 coplot(y ~ x | z),其中x 和y是数值型向量,z是同长度的因子。 对z的每一水平,绘制相应组的x和y的散点图
R缺省的图形边空常常太大,以至于有时图形窗口较小时边空占了整个图形的很大一部分。
R可以在同一页面开若干个按行、列排列的窗格,在每个窗格中可以作一 幅图。每个图有自己的边空,而所有图的外面可以包一个“外边空”。
一页多图用 mfrow 参数或 mfcol 参数规定,如
函数 mtext 用来在外边空加文字标注。其用法为
在多图环境中还可以用 mfg 参数来直接跳到某一个窗格,比如
可以不使用多图环境而直接在页面中的任意位置产生一个窗格来绘图,参数为 fig ,如:
先用as.factor()转化成因子。因为levels()函数里面必须是因子。
dat$Genre没有转化成因子形式,as.factor(dat$Genre)就可以了
该消息表明文件的最后一行不以行尾 (EOL) 字符结尾(换行符 ( \n ) 或回车 + 换行符 ( \r\n ))。此消息的初衷是警告您该文件可能不完整;大多数数据文件都有一个 EOL 字符作为文件中的最后一个字符。
这是因为R读取文件的时候,是一整段character,所以它只会返回1,适当给他分一下段。
R语言学习笔记之聚类分析
使用k-means聚类所需的包:
factoextra
cluster #加载包
library(factoextra)
library(cluster)l
#数据准备
使用内置的R数据集USArrests
#load the dataset
data("USArrests")
#remove any missing value (i.e, NA values for not available)
#That might be present in the data
USArrests <- na.omit(USArrests)#view the first 6 rows of the data
head(USArrests, n=6)
在此数据集中,列是变量,行是观测值
在聚类之前我们可以先进行一些必要的数据检查即数据描述性统计,如平均值、标准差等
desc_stats <- data.frame( Min=apply(USArrests, 2, min),#minimum
Med=apply(USArrests, 2, median),#median
Mean=apply(USArrests, 2, mean),#mean
SD=apply(USArrests, 2, sd),#Standard deviation
Max=apply(USArrests, 2, max)#maximum
)
desc_stats <- round(desc_stats, 1)#保留小数点后一位head(desc_stats)
变量有很大的方差及均值时需进行标准化
df <- scale(USArrests)
#数据集群性评估
使用get_clust_tendency()计算Hopkins统计量
res <- get_clust_tendency(df, 40, graph = TRUE)
res$hopkins_stat
## [1] 0.3440875
#Visualize the dissimilarity matrix
res$plot
Hopkins统计量的值<0.5,表明数据是高度可聚合的。另外,从图中也可以看出数据可聚合。
#估计聚合簇数
由于k均值聚类需要指定要生成的聚类数量,因此我们将使用函数clusGap()来计算用于估计最优聚类数。函数fviz_gap_stat()用于可视化。
set.seed(123)
## Compute the gap statistic
gap_stat <- clusGap(df, FUN = kmeans, nstart = 25, K.max = 10, B = 500)
# Plot the result
fviz_gap_stat(gap_stat)
图中显示最佳为聚成四类(k=4)
#进行聚类
set.seed(123)
km.res <- kmeans(df, 4, nstart = 25)
head(km.res$cluster, 20)
# Visualize clusters using factoextra
fviz_cluster(km.res, USArrests)
#检查cluster silhouette图
Recall that the silhouette measures (SiSi) how similar an object ii is to the the other objects in its own cluster versus those in the neighbor cluster. SiSi values range from 1 to - 1:
A value of SiSi close to 1 indicates that the object is well clustered. In the other words, the object ii is similar to the other objects in its group.
A value of SiSi close to -1 indicates that the object is poorly clustered, and that assignment to some other cluster would probably improve the overall results.
sil <- silhouette(km.res$cluster, dist(df))
rownames(sil) <- rownames(USArrests)
head(sil[, 1:3])
#Visualize
fviz_silhouette(sil)
图中可以看出有负值,可以通过函数silhouette()确定是哪个观测值
neg_sil_index <- which(sil[, "sil_width"] <0)
sil[neg_sil_index, , drop = FALSE]
## cluster neighbor sil_width
## Missouri 3 2 -0.07318144
#eclust():增强的聚类分析
与其他聚类分析包相比,eclust()有以下优点:
简化了聚类分析的工作流程
可以用于计算层次聚类和分区聚类
eclust()自动计算最佳聚类簇数。
自动提供Silhouette plot
可以结合ggplot2绘制优美的图形
#使用eclust()的K均值聚类
# Compute k-means
res.km <- eclust(df, "kmeans")
# Gap statistic plot
fviz_gap_stat(res.km$gap_stat)
# Silhouette plotfviz_silhouette(res.km)
## cluster size ave.sil.width
## 1 1 13 0.31
## 2 2 29 0.38
## 3 3 8 0.39
#使用eclust()的层次聚类
# Enhanced hierarchical clustering
res.hc <- eclust(df, "hclust") # compute hclust
fviz_dend(res.hc, rect = TRUE) # dendrogam
#下面的R代码生成Silhouette plot和分层聚类散点图。
fviz_silhouette(res.hc) # silhouette plot
## cluster size ave.sil.width
## 1 1 19 0.26
## 2 2 19 0.28
## 3 3 12 0.43
fviz_cluster(res.hc) # scatter plot
#Infos
This analysis has been performed using R software (R version 3.3.2)