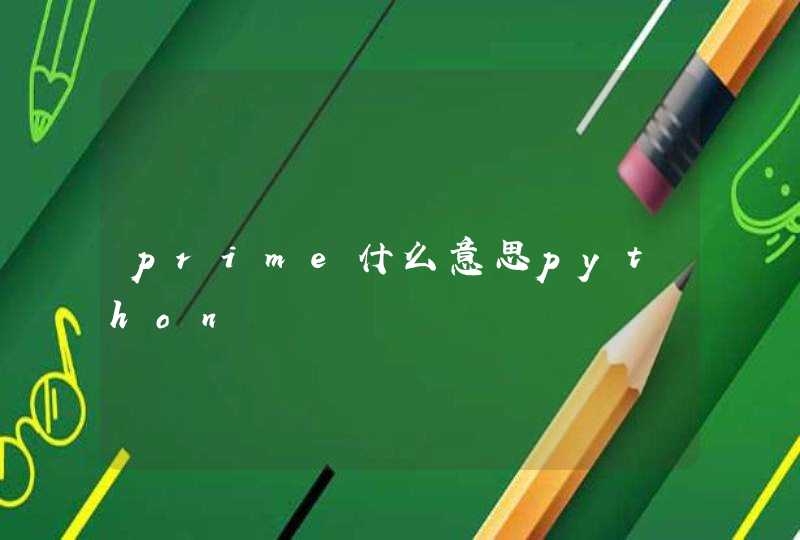![R语言 > pairs(iris[,1:4]) > pairs(iris[1:4]) 这俩语句画的图一样,,那个逗号是干嘛的??](/aiimages/R%E8%AF%AD%E8%A8%80+%26amp%3Bgt%3B+pairs%28iris%5B%2C1%3A4%5D%29+%26amp%3Bgt%3B+pairs%28iris%5B1%3A4%5D%29+%E8%BF%99%E4%BF%A9%E8%AF%AD%E5%8F%A5%E7%94%BB%E7%9A%84%E5%9B%BE%E4%B8%80%E6%A0%B7%EF%BC%8C%EF%BC%8C%E9%82%A3%E4%B8%AA%E9%80%97%E5%8F%B7%E6%98%AF%E5%B9%B2%E5%98%9B%E7%9A%84%EF%BC%9F%EF%BC%9F.png)

































我们的存在离不开信息,我们依赖数据而存在,大脑就是一个黑箱,连接黑箱和外界的就是你的感官,在时间流里,各种数据被我们的感官提取,传入大脑。大脑可以对信息进行建模,理解信息,预测未来,通过肌肉控制器对外发出指令,改变外在的世界。
语言是这整个环节当中一个非常重要的因素,语言可以将数据在不同的大脑模型间传递,这些模型就组成了更为强大的网络,创造了高等文明。语言也是一种客观的记录工具。
我们人类的语言是对我们存在世界的一种映射,而计算机语言则很局限,仅为执行任务而生;我们的大脑能够对整个世界建模,能对将这世界的每一个物体抽象建模。
人类之所以强大,是因为它是作为一个整体存在的,任何个体都只会是这个网络中的一个节点。
我们一直存在于大数据之中,只是现在我们更容易的获取数据了。
如果我们理解了数据中存在的有规律的模式,我们就能做出有潜力的预测。
机器学习,发明计算机算法,把数据转化为智能行为。(核心循环的三者:现有数据;统计方法;计算能力)
数据挖掘,从大型数据库中产生新的洞察,侧重寻找有价值的信息;机器学习侧重于执行一个已知的任务。
(在商业上一个重要的应用就是根据客户的购买行为,预测其需求,从而为其提供个性化的服务和推销。)
1.2 学习理论
定义:如果机器能够获取经验并且能利用它们,在以后的类似经验中能够提高它的表现,这种行为就是机器的学习。
学习过程:
数据输入,观察(抽象并提取信息),记忆(将信息存储在大脑的某个文件里),回忆(打开大脑里的文件)
抽象化,将数据转换成更宽泛的表现形式
一般化,应用抽象数据来形成行动的基础
举例:学习&考试
过目不忘并不是一种本领,而是一种低级的作弊方式,你没有深刻理解知识,数据本身并不能为你做出决策;必须理解核心概念(建立大纲、概念图),明确信息之间的关系,以主题为中心(这就是知识抽象化)。 一般化,需要大量抽象数据,理解如何将已有知识应用到未知场景中(好的老师能做到这两点)。
1.2.1 抽象化和知识表达
原始数据是没有意义的,仅仅是一些01或符号而已,抽象化赋予数据以具体含义。
idea 和 reality,只是语言的抽象连接。
知识表达中,将原始数据概括在一个模型里,该模型就是数据间结构化的显式描述。(方程,图表,分类都是模型)
学习的任务和所分析数据的类型决定选择使用什么模型。
用一个特定的模型来拟合数据集的过程称为训练(还没达到学习,这还只是抽象化,学习还包括一般化)。
当模型被训练后,数据转换为一个汇总了原始信息的抽象形式。模型提供了数据之间的关系或联系。
1.2.2 一般化
抽象化过程中可能发现无数的内在关系,有多种方法可以对内在关系建模(集合),为了预测,必须选定模型。
定义:一般化描述了把抽象化的知识转换成可以用于行动的形式。是训练过程中对所有可用于数据抽象化的模型的搜索过程。
一般不会遍历每一种可能来确定模型,而是用启发式方法。
偏差,就是系统误差,是模型与真实值之间的差距。偏差是普遍存在的。
一般化的最后一步就是在存在偏差的情况下判断模型的成功性。
数据中必然存在噪音,模型不能拟合噪音而造成过度拟合,模型处理噪音数据的好坏是判断模型成功与否的重要方面。
数据科学和机器学习是该时代最需求的技术,这一需求促使每个人都学习不同的库和软件包以实现它们。这篇博客文章将重点介绍用于数据科学和机器学习的Python库。这些是您掌握市场上最被炒作的两项技能的库。
以下是此博客中将涉及的主题列表:
数据科学与机器学习导论为什么要使用Python进行数据科学和机器学习?用于数据科学和机器学习的Python库用于统计的Python库用于可视化的Python库用于机器学习的Python库深度学习的Python库用于自然语言处理的Python库数据科学与机器学习导论
当我开始研究数据科学和机器学习时,总是有这个问题困扰我最大。是什么导致围绕这两个话题的热门话题?
嗡嗡声与我们生成的数据量有很大关系。数据是驱动ML模型所需的燃料,并且由于我们处在大数据时代,因此很清楚为什么将数据科学视为该时代最有希望的工作角色!
我会说数据科学和机器学习是技能,而不仅仅是技术。它们是从数据中获得有用的见解并通过建立预测模型解决问题所需的技能。
从形式上来讲,这就是两者的定义方式。
数据科学是从数据中提取有用信息以解决实际问题的过程。
机器学习是使机器学习如何通过提供大量数据来解决问题的过程。
这两个域是高度互连的。
机器学习是数据科学的一部分,它利用ML算法和其他统计技术来了解数据如何影响和发展业务。
为什么要使用Python?
Python在用于实现机器学习和数据科学的最流行的编程语言中排名第一。让我们了解为什么。
易于学习: Python使用非常简单的语法,可用于实现简单的计算,例如将两个字符串添加到复杂的过程中,例如构建复杂的ML模型。更少的代码:实施数据科学和机器学习涉及无数的算法。得益于Python对预定义包的支持,我们不必编写算法。为了使事情变得更容易,Python提供了一种“在编码时检查”的方法,从而减轻了测试代码的负担。预建库: Python有100多个预建库,用于实现各种ML和深度学习算法。因此,每次您要在数据集上运行算法时,只需要做的就是用单个命令安装和加载必要的程序包。预先构建的库的示例包括NumPy,Keras,Tensorflow,Pytorch等。与平台无关: Python可以在多个平台上运行,包括Windows,macOS,Linux,Unix等。在将代码从一个平台转移到另一个平台时,您可以使用诸如PyInstaller之类的软件包,该软件包将解决所有依赖性问题。大量的社区支持:除拥有大量支持者外,Python还拥有多个社区,团体和论坛,程序员可以在其中发布他们的错误并互相帮助。Python库
Python在AI和ML领域普及的唯一最重要的原因是,Python提供了数千个内置库,这些库具有内置功能和方法,可以轻松地进行数据分析,处理,处理,建模等。 。在下一节中,我们将讨论以下任务的库:
统计分析数据可视化数据建模与机器学习深度学习自然语言处理(NLP)统计分析
统计是数据科学和机器学习的最基本基础之一。所有ML和DL算法,技术等均基于统计的基本原理和概念。
Python附带了大量的库,仅用于统计分析。在此博客中,我们将重点介绍提供内置函数以执行最复杂的统计计算的顶级统计软件包。
这是用于统计分析的顶级Python库的列表:
NumPySciPyPandas统计模型NumPy
NumPy或数值Python是最常用的Python库之一。该库的主要功能是它支持用于数学和逻辑运算的多维数组。NumPy提供的功能可用于索引,分类,整形和传输图像和声波,这些图像和声波是多维实数数组。
以下是NumPy的功能列表:
执行简单到复杂的数学和科学计算对多维数组对象的强大支持以及用于处理数组元素的函数和方法的集合傅里叶变换和数据处理例程执行线性代数计算,这对于机器学习算法(例如线性回归,逻辑回归,朴素贝叶斯等)是必需的。SciPy
SciPy库建立在NumPy之上,是一组子软件包的集合,可帮助解决与统计分析有关的最基本问题。SciPy库用于处理使用NumPy库定义的数组元素,因此它通常用于计算使用NumPy无法完成的数学方程式。
这是SciPy的功能列表:
它与NumPy数组一起使用,提供了一个平台,提供了许多数学方法,例如数值积分和优化。它具有可用于矢量量化,傅立叶变换,积分,插值等子包的集合。提供完整的线性代数函数堆栈,这些函数可用于更高级的计算,例如使用k-means算法的聚类等。提供对信号处理,数据结构和数值算法,创建稀疏矩阵等的支持。Pandas
Pandas是另一个重要的统计库,主要用于统计,金融,经济学,数据分析等广泛领域。该库依赖于NumPy数组来处理Pandas数据对象。NumPy,Pandas和SciPy在执行科学计算,数据处理等方面都严重依赖彼此。
我经常被要求在Pandas,NumPy和SciPy中选择最好的,但是,我更喜欢使用它们,因为它们彼此之间非常依赖。Pandas是处理大量数据的最佳库之一,而NumPy对多维数组具有出色的支持,另一方面,Scipy提供了一组执行大多数统计分析任务的子包。
以下是Pandas的功能列表:
使用预定义和自定义索引创建快速有效的DataFrame对象。它可用于处理大型数据集并执行子集,数据切片,索引等。提供用于创建Excel图表和执行复杂数据分析任务的内置功能,例如描述性统计分析,数据整理,转换,操作,可视化等。提供对处理时间序列数据的支持统计模型
StatsModels Python软件包建立在NumPy和SciPy之上,是创建统计模型,数据处理和模型评估的最佳选择。除了使用SciPy库中的NumPy数组和科学模型外,它还与Pandas集成以进行有效的数据处理。该库以统计计算,统计测试和数据探索而闻名。
以下是StatsModels的功能列表:
NumPy和SciPy库中找不到的执行统计检验和假设检验的最佳库。提供R样式公式的实现,以实现更好的统计分析。它更隶属于统计人员经常使用的R语言。由于它广泛支持统计计算,因此通常用于实现广义线性模型(GLM)和普通最小二乘线性回归(OLM)模型。包括假设检验(零理论)在内的统计检验是使用StatsModels库完成的。因此,它们是用于统计分析的最常用和最有效的Python库。现在让我们进入数据科学和机器学习中的数据可视化部分。
数据可视化
图片说出一千多个单词。我们都听说过关于艺术方面的引用,但是,对于数据科学和机器学习也是如此。
数据可视化就是通过图形表示有效地表达来自数据的关键见解。它包括图形,图表,思维导图,热图,直方图,密度图等的实现,以研究各种数据变量之间的相关性。
在本博客中,我们将重点介绍最好的Python数据可视化软件包,这些软件包提供内置函数来研究各种数据功能之间的依赖关系。
这是用于数据可视化的顶级Python库的列表:
MatplotlibMatplotlibPlotyBokehMatplotlib
Matplotlib是Python中最基本的数据可视化软件包。它支持各种图形,例如直方图,条形图,功率谱,误差图等。它是一个二维图形库,可生成清晰明了的图形,这对于探索性数据分析(EDA)至关重要。
这是Matplotlib的功能列表:
Matplotlib通过提供选择合适的线条样式,字体样式,格式化轴等功能,使绘制图形变得极为容易。创建的图形可帮助您清楚地了解趋势,模式并进行关联。它们通常是推理定量信息的工具。它包含Pyplot模块,该模块提供了与MATLAB用户界面非常相似的界面。这是Matplotlib软件包的最佳功能之一。提供面向对象的API模块,以使用GUI工具(例如Tkinter,wxPython,Qt等)将图形集成到应用程序中。Matplotlib
Matplotlib库构成了Seaborn库的基础。与Matplotlib相比,Seaborn可用于创建更具吸引力和描述性的统计图。除了对数据可视化的广泛支持外,Seaborn还附带一个面向数据集的内置API,用于研究多个变量之间的关系。
以下是Seaborn的功能列表:
提供用于分析和可视化单变量和双变量数据点以及将数据与其他数据子集进行比较的选项。支持针对各种目标变量的线性回归模型的自动统计估计和图形表示。通过提供执行高级抽象的功能,构建用于构造多图网格的复杂可视化。带有许多内置主题,可用于样式设置和创建matplotlib图Ploty
Ploty是最知名的图形Python库之一。它提供了交互式图形,以了解目标变量和预测变量之间的依赖性。它可以用于分析和可视化统计,财务,商业和科学数据,以生成清晰明了的图形,子图,热图,3D图表等。
这是使Ploty成为最佳可视化库之一的功能列表:
它具有30多种图表类型,包括3D图表,科学和统计图,SVG地图等,以实现清晰的可视化。借助Ploty的Python API,您可以创建由图表,图形,文本和Web图像组成的公共/私有仪表板。使用Ploty创建的可视化以JSON格式序列化,因此您可以在R,MATLAB,Julia等不同平台上轻松访问它们。它带有一个称为Plotly Grid的内置API,该API可让您直接将数据导入Ploty环境。Bokeh
Bokeh是Python中交互性最强的库之一,可用于为Web浏览器构建描述性的图形表示形式。它可以轻松处理庞大的数据集并构建通用图,从而有助于执行广泛的EDA。Bokeh提供定义最完善的功能,以构建交互式绘图,仪表板和数据应用程序。
这是Bokeh的功能列表:
使用简单的命令帮助您快速创建复杂的统计图支持HTML,笔记本和服务器形式的输出。它还支持多种语言绑定,包括R,Python,lua,Julia等。Flask和django也与Bokeh集成在一起,因此您也可以在这些应用程序上表达可视化效果它提供了对转换为其他库(如matplotlib,seaborn,ggplot等)中编写的可视化文件的支持因此,这些是用于数据可视化的最有用的Python库。现在,让我们讨论用于实现整个机器学习过程的顶级Python库。
机器学习
创建可以准确预测结果或解决特定问题的机器学习模型是任何数据科学项目中最重要的部分。
实施ML,DL等涉及对数千行代码进行编码,当您要创建通过神经网络解决复杂问题的模型时,这可能变得更加麻烦。但值得庆幸的是,我们无需编写任何算法,因为Python随附了多个软件包,仅用于实现机器学习技术和算法。
在此博客中,我们将重点介绍提供内置函数以实现所有ML算法的顶级ML软件包。
以下是用于机器学习的顶级Python库的列表:
Scikit-learnXGBoostElI5Scikit-learn
Scikit-learn是最有用的Python库之一,是用于数据建模和模型评估的最佳库。它附带了无数功能,其唯一目的是创建模型。它包含所有有监督的和无监督的机器学习算法,并且还具有用于集合学习和促进机器学习的定义明确的功能。
以下是Scikit学习的功能列表:
提供一组标准数据集,以帮助您开始使用机器学习。例如,著名的Iris数据集和Boston House Price数据集是Scikit-learn库的一部分。用于执行有监督和无监督机器学习的内置方法。这包括解决,聚类,分类,回归和异常检测问题。带有用于特征提取和特征选择的内置功能,可帮助识别数据中的重要属性。它提供了执行交叉验证以评估模型性能的方法,还提供了用于优化模型性能的参数调整功能。XGBoost
XGBoost代表“极端梯度增强”,它是执行Boosting Machine Learning的最佳Python软件包之一。诸如LightGBM和CatBoost之类的库也同样配备了定义明确的功能和方法。建立该库的主要目的是实现梯度提升机,该梯度提升机用于提高机器学习模型的性能和准确性。
以下是其一些主要功能:
该库最初是用C ++编写的,被认为是提高机器学习模型性能的最快,有效的库之一。核心的XGBoost算法是可并行化的,并且可以有效地利用多核计算机的功能。这也使该库足够强大,可以处理大量数据集并跨数据集网络工作。提供用于执行交叉验证,参数调整,正则化,处理缺失值的内部参数,还提供scikit-learn兼容的API。该库经常在顶级的数据科学和机器学习竞赛中使用,因为它一直被证明优于其他算法。ElI5
ELI5是另一个Python库,主要致力于改善机器学习模型的性能。该库相对较新,通常与XGBoost,LightGBM,CatBoost等一起使用,以提高机器学习模型的准确性。
以下是其一些主要功能:
提供与Scikit-learn软件包的集成,以表达功能重要性并解释决策树和基于树的集成的预测。它分析并解释了XGBClassifier,XGBRegressor,LGBMClassifier,LGBMRegressor,CatBoostClassifier,CatBoostRegressor和catboost所做的预测。它提供了对实现多种算法的支持,以便检查黑盒模型,其中包括TextExplainer模块,该模块可让您解释由文本分类器做出的预测。它有助于分析包括线性回归器和分类器在内的scikit学习通用线性模型(GLM)的权重和预测。深度学习
机器学习和人工智能的最大进步是通过深度学习。随着深度学习的介绍,现在可以构建复杂的模型并处理庞大的数据集。幸运的是,Python提供了最好的深度学习软件包,可帮助构建有效的神经网络。
在此博客中,我们将专注于提供用于实现复杂的神经网络的内置功能的顶级深度学习软件包。
以下是用于深度学习的顶级Python库的列表:
TensorFlowPytorchKerasTensorFlow
TensorFlow是用于深度学习的最佳Python库之一,是一个用于跨各种任务进行数据流编程的开源库。它是一个符号数学库,用于构建强大而精确的神经网络。它提供了直观的多平台编程界面,可在广阔的领域中实现高度扩展。
以下是TensorFlow的一些关键功能:
它允许您构建和训练多个神经网络,以帮助适应大型项目和数据集。除支持神经网络外,它还提供执行统计分析的功能和方法。例如,它带有用于创建概率模型和贝叶斯网络(例如伯努利,Chi2,Uniform,Gamma等)的内置功能。该库提供了分层的组件,这些组件可以对权重和偏差执行分层的操作,并且还可以通过实施正则化技术(例如批标准化,丢包等)来提高模型的性能。它带有一个称为TensorBoard的可视化程序,该可视化程序创建交互式图形和可视化图形以了解数据功能的依赖性。Pytorch
Pytorch是一个基于Python的开源科学计算软件包,用于在大型数据集上实施深度学习技术和神经网络。Facebook积极地使用此库来开发神经网络,以帮助完成各种任务,例如面部识别和自动标记。
以下是Pytorch的一些主要功能:
提供易于使用的API与其他数据科学和机器学习框架集成。与NumPy一样,Pytorch提供了称为Tensors的多维数组,与NumPy不同,它甚至可以在GPU上使用。它不仅可以用于对大型神经网络进行建模,而且还提供了一个界面,具有200多种用于统计分析的数学运算。创建动态计算图,以在代码执行的每个点建立动态图。这些图有助于时间序列分析,同时实时预测销售量。Keras
Keras被认为是Python中最好的深度学习库之一。它为构建,分析,评估和改进神经网络提供全面支持。Keras基于Theano和TensorFlow Python库构建,该库提供了用于构建复杂的大规模深度学习模型的附加功能。
以下是Keras的一些关键功能:
为构建所有类型的神经网络提供支持,即完全连接,卷积,池化,循环,嵌入等。对于大型数据集和问题,可以将这些模型进一步组合以创建完整的神经网络它具有执行神经网络计算的内置功能,例如定义层,目标,激活功能,优化器和大量工具,使处理图像和文本数据更加容易。它带有一些预处理的数据集和经过训练的模型,包括MNIST,VGG,Inception,SqueezeNet,ResNet等。它易于扩展,并支持添加包括功能和方法的新模块。自然语言处理
您是否曾经想过Google如何恰当地预测您要搜索的内容?Alexa,Siri和其他聊天机器人背后的技术是自然语言处理。NLP在设计基于AI的系统中发挥了巨大作用,该系统有助于描述人类语言与计算机之间的交互。
在此博客中,我们将重点介绍提供内置功能以实现基于高级AI的系统的顶级自然语言处理包。
这是用于自然语言处理的顶级Python库的列表:
NLTKspaCyGensimNLTK(自然语言工具包)
NLTK被认为是分析人类语言和行为的最佳Python软件包。NLTK库是大多数数据科学家的首选,它提供易于使用的界面,其中包含50多种语料库和词汇资源,有助于描述人与人之间的互动以及构建基于AI的系统(例如推荐引擎)。
这是NLTK库的一些关键功能:
提供一套数据和文本处理方法,用于文本分析的分类,标记化,词干,标记,解析和语义推理。包含用于工业级NLP库的包装器,以构建复杂的系统,以帮助进行文本分类并查找人类语音的行为趋势和模式它带有描述计算语言学实现的综合指南和完整的API文档指南,可帮助所有新手开始使用NLP。它拥有庞大的用户和专业人员社区,它们提供全面的教程和快速指南,以学习如何使用Python进行计算语言学。spaCy
spaCy是一个免费的开源Python库,用于实现高级自然语言处理(NLP)技术。当您处理大量文本时,重要的是要了解文本的形态学意义以及如何将其分类以理解人类语言。通过spaCY可以轻松实现这些任务。
这是spaCY库的一些关键功能:
除了语言计算外,spaCy还提供了单独的模块来构建,训练和测试统计模型,从而更好地帮助您理解单词的含义。带有各种内置的语言注释,可帮助您分析句子的语法结构。这不仅有助于理解测试,还有助于查找句子中不同单词之间的关系。它可用于对包含缩写和多个标点符号的复杂嵌套令牌应用令牌化。除了非常强大和快速之外,spaCy还提供对51种以上语言的支持。Gensim
Gensim是另一个开源Python软件包,其建模旨在从大型文档和文本中提取语义主题,以通过统计模型和语言计算来处理,分析和预测人类行为。无论数据是原始数据还是非结构化数据,它都有能力处理庞大的数据。
以下是Genism的一些主要功能:
它可用于构建可通过理解每个单词的统计语义来有效分类文档的模型。它带有诸如Word2Vec,FastText,潜在语义分析之类的文本处理算法,这些算法研究文档中的统计共现模式,以过滤掉不必要的单词并构建仅具有重要功能的模型。提供可以导入并支持各种数据格式的I / O包装器和读取器。它具有简单直观的界面,可供初学者轻松使用。API学习曲线也很低,这解释了为什么许多开发人员喜欢此库。
在从事数据分析行业中,我们都会从R与Python当中进行选择,但是,从这两个异常强大、灵活好用的数据分析语中选择,却是非常难以选择的。
为了让大家能选择出更适合自己的语言,我们将两种语言进行简单的对比。
Stack Overflow趋势对比
相关推荐:《Python视频教程》
上图显示了自从2008年(Stack Overflow 成立)以来,这两种语言随着时间的推移而发生的变化。
R和Python在数据科学领域展开激烈竞争,我们来看看他们各自的平台份额,并将2016与2017年进行比较:
我们再从适用场景、任务、数据处理能力、开放环境来分析:
适用场景
R适用于数据分析任务需要独立计算或单个服务器的应用场景。Python作为一种粘合剂语言,在数据分析任务中需要与Web应用程序集成或者当一条统计代码需要插入到生产数据库中时,使用Python更好。
任务
在进行探索性统计分析时,R胜出。它非常适合初学者,统计模型仅需几行代码即可实现。Python作为一个完整而强大的编程语言,是部署用于生产使用的算法的有力工具。
数据处理能力
有了大量针对专业程序员以及非专业程序员的软件包和库的支持,不管是执行统计测试还是创建机器学习模型,R语言都得心应手。
Python最初在数据分析方面不是特别擅长,但随着NumPy、Pandas以及其他扩展库的推出,它已经逐渐在数据分析领域获得了广泛的应用。
开发环境
对于R语言,需要使用R Studio。对于Python,有很多Python IDE可供选择,其中Spyder和IPython Notebook是最受欢迎的。
R 和 Python 详细对比
R和Python之间有很强的关联,并且这两种语言日益普及,很难说选对其一,事实上日常用户和数据科学家可以同时利用这两种语言。