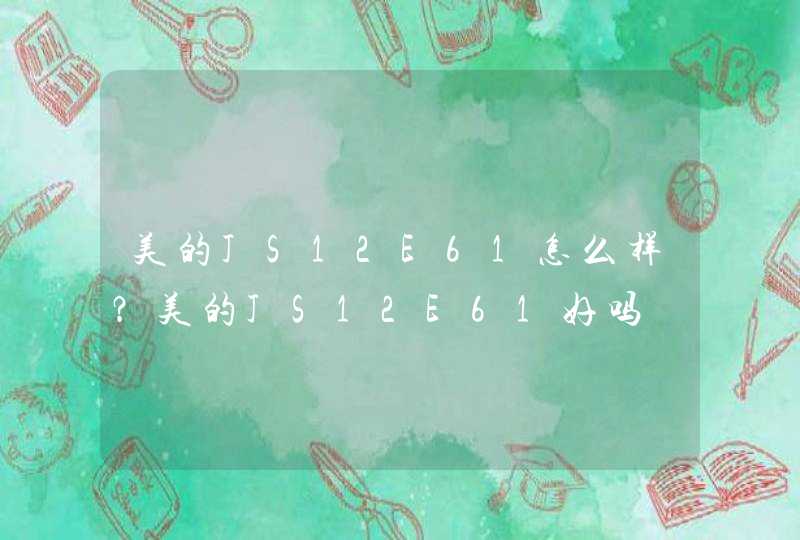方法1:把中文字替换成两个字母。然后计算长度。
方法2:直接判断中文,长度+2。
运用的方法大同小异。都是通过正则表达式,写unicode编码。
方法1中
[\u4e00-\u9fa5]:匹配中文字符
[^\x0000-\x00ff]:匹配双字节字符(包括中文字)
正则表达示 /[\u4e00-\u9fa5]/g 的 g 必须要,global,全部都要检查的意思。没有的话输出的是(2333aa哈)
方法2中的函数
扩展:
一般来说英文是1个,中文是两个。但是会根据编码方式不同而不同。以下是搬运:英文字母和中文汉字在不同字符集编码下的字节数英文字母:字节数 : 1编码:GB2312字节数 : 1编码:GBK字节数 : 1编码:GB18030字节数 : 1编码:ISO-8859-1字节数 : 1编码:UTF-8字节数 : 4编码:UTF-16字节数 : 2编码:UTF-16BE字节数 : 2编码:UTF-16LE中文汉字:字节数 : 2编码:GB2312字节数 : 2编码:GBK字节数 : 2编码:GB18030字节数 : 1编码:ISO-8859-1字节数 : 3编码:UTF-8字节数 : 4编码:UTF-16字节数 : 2编码:UTF-16BE字节数 : 2编码:UTF-16LE