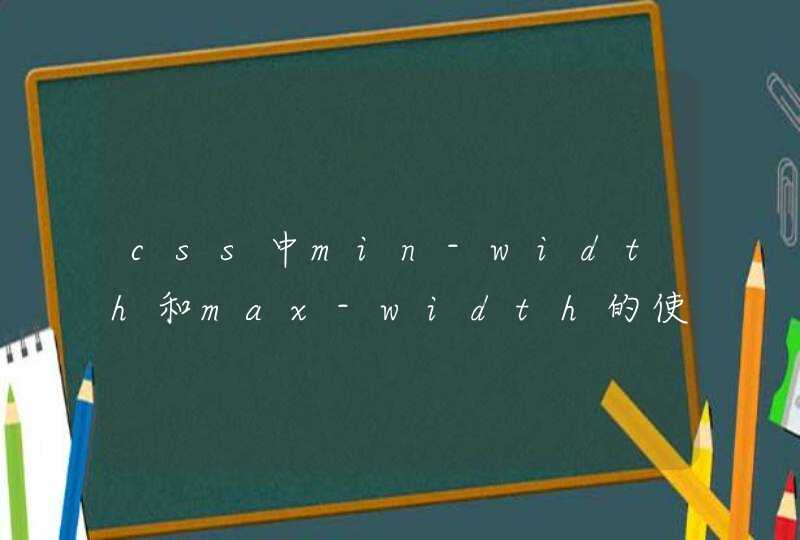


































定义一颗树,JS中常见的树形数据结构如下,children属性对应的是子树
let tree = [
{
id: '1',
name: '节点1',
children: [
{
id: '1-1',
name: '节点1-1'
}
]
},
{
id: '2',
name: '节点2',
children: [
{
id: '2-1',
name: '节点2-1'
},
{
id: '2-2',
name: '节点2-2',
children: [
{
id: '2-2-1',
name: '节点2-2-1'
}
]
}
]
},
{
id: '3',
name: '节点3'
}
]
二、深度优先遍历(DFS)
1、递归实现
function treeIterator(tree, func) {
tree.forEach((node) =>{
func(node)
node.children &&treeIterator(node.children, func)
})
}
实现逻辑简述:定义treeIterator函数,传入tree(树)和func(回调函数)两个参数,遍历tree数组,执行回调函数,如果当前节点存在children,则递归调用。
函数调用验证:调用treeIterator函数,传入上文定义好的树结构数组,打印出每个节点的name值。
treeIterator(tree, (node) =>{
console.log(node.name)
})
控制台打印结果如下:
2、循环实现
function treeIterator(tree, func) {
let node, curTree = [...tree]
while ((node = curTree.shift())) {
func(node)
node.children &&curTree.unshift(...node.children)
}
}
实现逻辑简述:
(1)定义node作为当前节点,curTree为传入的树(不影响原数组tree);
(2)执行while循环,curTree数组第一个元素从其中删除,并返回第一个元素赋值给node;
(3)①执行回调函数;②如果当前节点存在子树,则追加到curTree数组的开头,继续执行循环,直到curTree没有元素为止。
函数调用验证:参考上述递归实现验证,方式和结果一致。
三、广度优先遍历(BFS)
function treeIterator(tree, func) {
let node, curTree = [...tree]
while ((node = curTree.shift())) {
func(node)
node.children &&curTree.push(...node.children)
}
}
实现逻辑简述:和上述深度优先遍历的循环实现差不多。区别在于如果当前节点存在子树,则追加到list数组的末尾。
title: JS树结构数据的遍历date: 2022-04-14
description: 针对项目中出现树形结构数据的时候,我们怎样去操作他
项目中我们会经常出现对树形结构的遍历、查找和转换的场景,比如说DOM树、族谱、社会机构、组织架构、权限、菜单、省市区、路由、标签等等。那针对这些场景和数据,我们又如何去遍历和操作,有什么方式或者技巧可以简化我们的实现思路。下面我们将针对常规出现的场景去总结一下我们的遍历方式
树的特点
1、每个节点都只有有限个子节点或无子节点;
2、没有父节点的节点称为根节点;
3、每一个非根节点有且只有一个父节点;
4、除了根节点外,每个子节点可以分为多个不相交的子树;
5、树里面没有环路
下面的图片表示一颗树
在下面的JS中我们由多棵树组成我们的数据
在这数据中我们如何评判数据是否为叶节点(也就是最后一级),我们每个节点都会存在children属性,如果不存在children属性或者children不是一个数组或者children为数组且长度为0我们则认为他是一个叶节点
我们针对树结构的操作离不开遍历,遍历的话又分为广度优先遍历、深度优先遍历。其中深度优先遍历可以通过递归和循环的方式实现,而广度优先遍历的话是非递归的
从上往下对每一层依次访问,在每一层中,从左往右(也可以从右往左)访问结点,访问完一层就进入下一层,直到没有结点可以访问为止。即访问树结构的第n+1层前必须先访问完第n层。
简单的说,BFS是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止。
所以我们的实现思路是,维护一个队列,队列的初始值为树结构根节点组成的列表,重复执行以下步骤直到队列为空:
取出队列中的第一个元素,进行访问相关操作,然后将其后代元素(如果有)全部追加到队列最后。
深度优先搜索算法(英语:Depth-First-Search,DFS)是一种用于遍历或搜索树或图的算法。这个算法会尽可能深的搜索树的分支。当节点v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止
1、先序遍历
访问子树的时候,先访问根再访问根的子树
2、后序遍历
访问子树的时候,先访问子树再访问根
1、先序遍历
先序遍历与广度优先循环实现类似,要维护一个队列,不同的是子节点不追加到队列最后,而是加到队列最前面
2、后序遍历
后序遍历就略微复杂一点,我们需要不断将子树扩展到根节点前面去,执行列表遍历,并且通过一个临时对象维护一个id列表,当遍历到某个节点如果它没有子节点或者它本身已经存在于我们的临时id列表,则执行访问操作,否则继续扩展子节点到当前节点前面
对于树结构的遍历操作,其实递归是最基础,也是最容易理解的。递归本身就是循环的思想,所以可以用循环来改写递归,以上的方式在项目中已经廊括了大部分的场景了,我们在日常开发中可以根据场景或者需要去选择我们的遍历方式,或者基于此对他进行调整和优化,至于每种方式的空间复杂度和时间复杂度我们在这个地方就不去尝试了,各位感兴趣可以自己去验证。
广度优先搜索
树的遍历
深度优先搜索
图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS)
二叉树遍历(前序,后序,中序,层次)递归与迭代实现JavaScript
JS树结构操作:查找、遍历、筛选、树和列表相互转换
1、方法思路使用js数组自带的filter()方法;数据格式要求,父子节点通过,Id,ParentId进行关联。默认父结节id为0。
样例数据:var jsonData = [{"id":"1","pid":"0","name":"家用电器"}, {"id":"4","pid":"1","name":"大家电"}, {"id":"5","pid":"1","name":"生活电器"}, {"id":"2","pid":"0","name":"服饰"}, {"id":"3","pid":"0","name":"化妆"}, {"id":"7","pid":"4","name":"空调"}, {"id":"8","pid":"4","name":"冰箱"}, {"id":"9","pid":"4","name":"洗衣机"}, {"id":"10","pid":"4","name":"热水器"}, {"id":"11","pid":"3","name":"面部护理"}, {"id":"12","pid":"3","name":"口腔护理"}, {"id":"13","pid":"2","name":"男装"}, {"id":"14","pid":"2","name":"女装"}, {"id":"15","pid":"7","name":"海尔空调"}, {"id":"16","pid":"7","name":"美的空调"}, {"id":"19","pid":"5","name":"加湿器"}, {"id":"20","pid":"5","name":"电熨斗"}]
2、实现方法:
function creatTreeData(list){
var clonelist = JSON.parse(JSON.stringify(list))
var result =clonelist.filter(function(father){
var childlist = clonelist.filter(function(child){
return father.id= child.pid
})
if(childlist.length>0){
father.children=childlist
}
return father.pid ==0
})
return result
}
3、方法封装
function treeData(list,id,pid,children){
var clone = JSON.parse(JSON.stringify(list))
return clone.filter(function(father){
var childlist =clone.filter(function(child){
return father[id]==child[pid]
})
if(childlist.length>0){
father[children]=childlist
}
return father[pid]==0
})
}