



























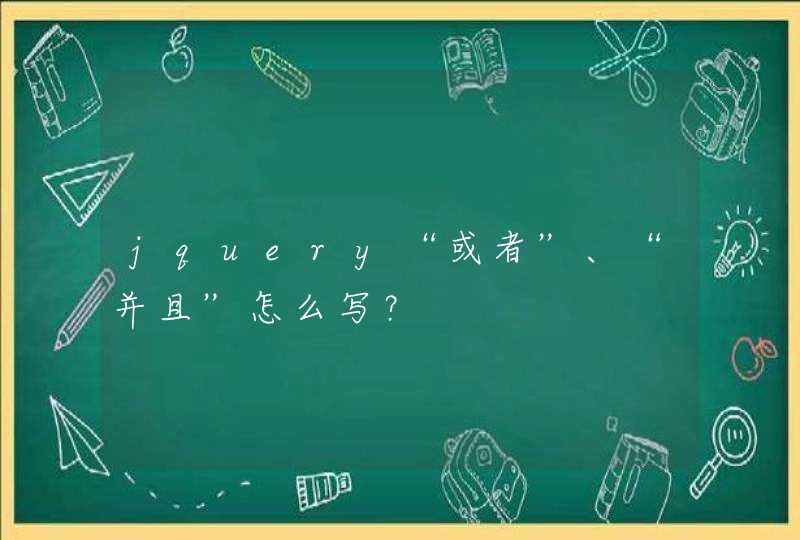











方法名就是 atob 和 btoa ,具体语法如下:
IE8/IE9的polyfill
当下,仍有不少PC项目还需要兼容IE9,所以,我们可以专门针对这些浏览器再引入一段ployfill脚本或者一个JS文件即可。
[if IE] 表示所有IE浏览器,由于IE10+浏览器已经放弃了著名的IE条件注释的支持,Chrome等浏览器本身就不支持这个IE私有语法,因此,很天然的,上面一段script引入只在IE9-浏览器下有效。而我们本来就希望只IE8,IE9浏览器引入ployfill,于是正好完美衔接上。
也就是原生支持atob和btoa方法的浏览器认为就是一段无需关心的HTML注释,不支持atob和btoa的IE9及其以下浏览器则会加载我们的base64-polyfill.js,使浏览器也支持 window.btoa 和 window.atob 这个语法。
开源的 base64.js ,使用很简单,浏览器引入该JS文件,然后Base64编码这样:
解码就调用 decode 方法,如下:
function Base64() {
// private property
_keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
// public method for encoding
this.encode = function (input) {
var output = ""
var chr1, chr2, chr3, enc1, enc2, enc3, enc4
var i = 0
input = _utf8_encode(input)
while (i <input.length) {
chr1 = input.charCodeAt(i++)
chr2 = input.charCodeAt(i++)
chr3 = input.charCodeAt(i++)
enc1 = chr1 >>2
enc2 = ((chr1 &3) <<4) | (chr2 >>4)
enc3 = ((chr2 &15) <<2) | (chr3 >>6)
enc4 = chr3 &63
if (isNaN(chr2)) {
enc3 = enc4 = 64
} else if (isNaN(chr3)) {
enc4 = 64
}
output = output +
_keyStr.charAt(enc1) + _keyStr.charAt(enc2) +
_keyStr.charAt(enc3) + _keyStr.charAt(enc4)
}
return output
}
// public method for decoding
this.decode = function (input) {
var output = ""
var chr1, chr2, chr3
var enc1, enc2, enc3, enc4
var i = 0
input = input.replace(/[^A-Za-z0-9\+\/\=]/g, "")
while (i <input.length) {
enc1 = _keyStr.indexOf(input.charAt(i++))
enc2 = _keyStr.indexOf(input.charAt(i++))
enc3 = _keyStr.indexOf(input.charAt(i++))
enc4 = _keyStr.indexOf(input.charAt(i++))
chr1 = (enc1 <<2) | (enc2 >>4)
chr2 = ((enc2 &15) <<4) | (enc3 >>2)
chr3 = ((enc3 &3) <<6) | enc4
output = output + String.fromCharCode(chr1)
if (enc3 != 64) {
output = output + String.fromCharCode(chr2)
}
if (enc4 != 64) {
output = output + String.fromCharCode(chr3)
}
}
output = _utf8_decode(output)
return output
}
// private method for UTF-8 encoding
_utf8_encode = function (string) {
string = string.replace(/\r\n/g,"\n")
var utftext = ""
for (var n = 0n <string.lengthn++) {
var c = string.charCodeAt(n)
if (c <128) {
utftext += String.fromCharCode(c)
} else if((c >127) &&(c <2048)) {
utftext += String.fromCharCode((c >>6) | 192)
utftext += String.fromCharCode((c &63) | 128)
} else {
utftext += String.fromCharCode((c >>12) | 224)
utftext += String.fromCharCode(((c >>6) &63) | 128)
utftext += String.fromCharCode((c &63) | 128)
}
}
return utftext
}
// private method for UTF-8 decoding
_utf8_decode = function (utftext) {
var string = ""
var i = 0
var c = c1 = c2 = 0
while ( i <utftext.length ) {
c = utftext.charCodeAt(i)
if (c <128) {
string += String.fromCharCode(c)
i++
} else if((c >191) &&(c <224)) {
c2 = utftext.charCodeAt(i+1)
string += String.fromCharCode(((c &31) <<6) | (c2 &63))
i += 2
} else {
c2 = utftext.charCodeAt(i+1)
c3 = utftext.charCodeAt(i+2)
string += String.fromCharCode(((c &15) <<12) | ((c2 &63) <<6) | (c3 &63))
i += 3
}
}
return string
}
}
<html>
<head>
<script src="lib/base64.js" type="text/javascript"></script>
<script type="text/javascript">
var b = new Base64()
var str = b.encode("admin:admin")
alert("base64 encode:" + str)
str = b.decode(str)
alert("base64 decode:" + str)
</script>
</head>
<body>
</body>
</html>
获取到上传的文件myfile,创建一个fileRead文件对象,使用readAsDataURL方法可以将读取到的文件编码成Data URL。文件加载成功后,e.target.result就是文件图片所对应的base64编码。直接赋值给img的src,就能显示图片。
下面是onload里e对象打印的结果,可以看出e.target.result是文件图片的信息。
下面打印的是base64的编码,可以在img的src中直接引用,或者复制到浏览器搜索框里也能直接搜索图片。
使用canvas画一个填充色为红色的矩形,试点按钮后,使用canvas.toDataURL方法:返回一个包含图片展示的 data URI 。可以使用type参数其类型,默认为 PNG 格式。把得到的base64编码赋给img的src,显示图片。
结果图如下:
两种图片的base64的方法都很实用,项目开发中可能会遇到,今天来分享给大家。





























