










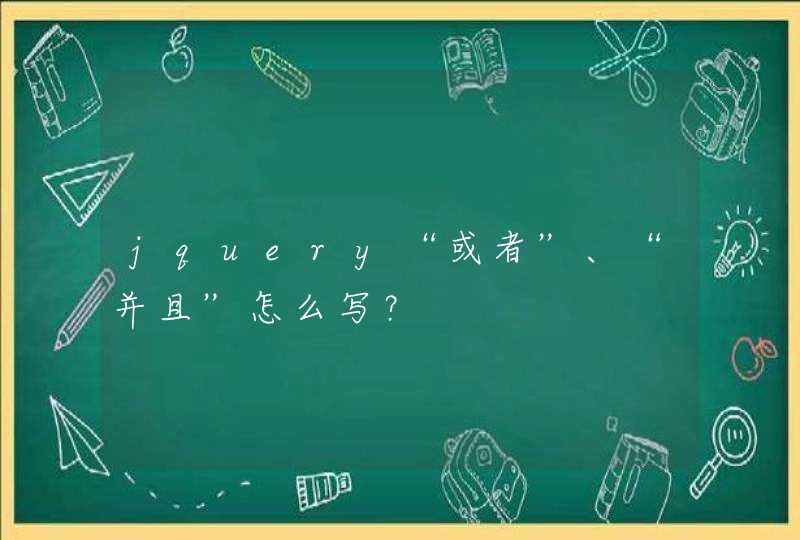





























k-nearest-neighbor-classifier
还是先严谨的介绍下。急切学习法(eager learner)是在接受待分类的新元组之前就构造了分类模型,学习后的模型已经就绪,急着对未知的元组进行分类,所以称为急切学习法,诸如决策树归纳,贝叶斯分类等都是急切学习法的例子。惰性学习法(lazy learner)正好与其相反,直到给定一个待接受分类的新元组之后,才开始根据训练元组构建分类模型,在此之前只是存储着训练元组,所以称为惰性学习法,惰性学习法在分类进行时做更多的工作。
本文的knn算法就是一种惰性学习法,它被广泛应用于模式识别。knn基于类比学习,将未知的新元组与训练元组进行对比,搜索模式空间,找出最接近未知元组的k个训练元组,这里的k即是knn中的k。这k个训练元祖就是待预测元组的k个最近邻。
balabala了这么多,是不是某些同学想大喊一声..speak Chinese! 还是来通俗的解释下,然后再来看上面的理论应该会明白很多。小时候妈妈会指着各种各样的东西教我们,这是小鸭子,这个红的是苹果等等,那我们哼哧哼哧的看着应答着,多次被教后再看到的时候我们自己就能认出来这些事物了。主要是因为我们在脑海像给这个苹果贴了很多标签一样,不只是颜色这一个标签,可能还有苹果的形状大小等等。这些标签让我们看到苹果的时候不会误认为是橘子。其实这些标签就对应于机器学习中的特征这一重要概念,而训练我们识别的过程就对应于泛化这一概念。一台iphone戴了一个壳或者屏幕上有一道划痕,我们还是能认得出来它,这对于我们人来说非常简单,但蠢计算机就不知道怎么做了,需要我们好好调教它,当然也不能过度调教2333,过度调教它要把其他手机也认成iphone那就不好了,其实这就叫过度泛化。
所以特征就是提取对象的信息,泛化就是学习到隐含在这些特征背后的规律,并对新的输入给出合理的判断。
我们可以看上图,绿色的圆代表未知样本,我们选取距离其最近的k个几何图形,这k个几何图形就是未知类型样本的邻居,如果k=3,我们可以看到有两个红色的三角形,有一个蓝色的三正方形,由于红色三角形所占比例高,所以我们可以判断未知样本类型为红色三角形。扩展到一般情况时,这里的距离就是我们根据样本的特征所计算出来的数值,再找出距离未知类型样本最近的K个样本,即可预测样本类型。那么求距离其实不同情况适合不同的方法,我们这里采用欧式距离。
综上所述knn分类的关键点就是k的选取和距离的计算。
2. 实现
我的数据是一个xls文件,那么我去npm搜了一下选了一个叫node-xlrd的包直接拿来用。
// node.js用来读取xls文件的包
var xls = require('node-xlrd')
然后直接看文档copy实例即可,把数据解析后插入到自己的数据结构里。
var data = []// 将文件中的数据映射到样本的属性var map = ['a','b','c','d','e','f','g','h','i','j','k']// 读取文件
xls.open('data.xls', function(err,bk){
if(err) {console.log(err.name, err.message)return}
var shtCount = bk.sheet.count
for(var sIdx = 0sIdx <shtCountsIdx++ ){
var sht = bk.sheets[sIdx],
rCount = sht.row.count,
cCount = sht.column.count
for(var rIdx = 0rIdx <rCountrIdx++){
var item = {}
for(var cIdx = 0cIdx <cCountcIdx++){
item[map[cIdx]] = sht.cell(rIdx,cIdx)
}
data.push(item)
}
}
// 等文件读取完毕后 执行测试
run()
})
然后定义一个构造函数Sample表示一个样本,这里是把刚生成的数据结构里的对象传入,生成一个新的样本。
// Sample表示一个样本
var Sample = function (object) {
// 把传过来的对象上的属性克隆到新创建的样本上
for (var key in object)
{
// 检验属性是否属于对象自身
if (object.hasOwnProperty(key)) {
this[key] = object[key]
}
}
}
再定义一个样本集的构造函数
// SampleSet管理所有样本 参数k表示KNN中的kvar SampleSet = function(k) {
this.samples = []
this.k = k
}
// 将样本加入样本数组
SampleSet.prototype.add = function(sample) {
this.samples.push(sample)
}
然后我们会在样本的原型上定义很多方法,这样每个样本都可以用这些方法。
// 计算样本间距离 采用欧式距离
Sample.prototype.measureDistances = function(a, b, c, d, e, f, g, h, i, j, k) {
for (var i in this.neighbors)
{
var neighbor = this.neighbors[i]
var a = neighbor.a - this.a
var b = neighbor.b - this.b
var c = neighbor.c - this.c
var d = neighbor.d - this.d
var e = neighbor.e - this.e
var f = neighbor.f - this.f
var g = neighbor.g - this.g
var h = neighbor.h - this.h
var i = neighbor.i - this.i
var j = neighbor.j - this.j
var k = neighbor.k - this.k
// 计算欧式距离
neighbor.distance = Math.sqrt(a*a + b*b + c*c + d*d + e*e + f*f + g*g + h*h + i*i + j*j + k*k)
}
}
// 将邻居样本根据与预测样本间距离排序
Sample.prototype.sortByDistance = function() {
this.neighbors.sort(function (a, b) {
return a.distance - b.distance
})
}
// 判断被预测样本类别
Sample.prototype.guessType = function(k) {
// 有两种类别 1和-1
var types = { '1': 0, '-1': 0 }
// 根据k值截取邻居里面前k个
for (var i in this.neighbors.slice(0, k))
{
var neighbor = this.neighbors[i]
types[neighbor.trueType] += 1
}
// 判断邻居里哪个样本类型多
if(types['1']>types['-1']){
this.type = '1'
} else {
this.type = '-1'
}
}
注意到我这里的数据有a-k共11个属性,样本有1和-1两种类型,使用truetype和type来预测样本类型和对比判断是否分类成功。
最后是样本集的原型上定义一个方法,该方法可以在整个样本集里寻找未知类型的样本,并生成他们的邻居集,调用未知样本原型上的方法来计算邻居到它的距离,把所有邻居按距离排序,最后猜测类型。
// 构建总样本数组,包含未知类型样本
SampleSet.prototype.determineUnknown = function() {
for (var i in this.samples)
{
// 如果发现没有类型的样本
if ( ! this.samples[i].type)
{
// 初始化未知样本的邻居
this.samples[i].neighbors = []
// 生成邻居集
for (var j in this.samples)
{
// 如果碰到未知样本 跳过
if ( ! this.samples[j].type)
continue
this.samples[i].neighbors.push( new Sample(this.samples[j]) )
}
// 计算所有邻居与预测样本的距离
this.samples[i].measureDistances(this.a, this.b, this.c, this.d, this.e, this.f, this.g, this.h, this.k)
// 把所有邻居按距离排序
this.samples[i].sortByDistance()
// 猜测预测样本类型
this.samples[i].guessType(this.k)
}
}
}
最后分别计算10倍交叉验证和留一法交叉验证的精度。
留一法就是每次只留下一个样本做测试集,其它样本做训练集。
K倍交叉验证将所有样本分成K份,一般均分。取一份作为测试样本,剩余K-1份作为训练样本。这个过程重复K次,最后的平均测试结果可以衡量模型的性能。
k倍验证时定义了个方法先把数组打乱随机摆放。
// helper函数 将数组里的元素随机摆放
function ruffle(array) {
array.sort(function (a, b) {
return Math.random() - 0.5
})
}
剩余测试代码好写,这里就不贴了。
测试结果为
用余弦距离等计算方式可能精度会更高。
3. 总结
knn算法非常简单,但却能在很多关键的地方发挥作用并且效果非常好。缺点就是进行分类时要扫描所有训练样本得到距离,训练集大的话会很慢。
可以用这个最简单的分类算法来入高大上的ML的门,会有点小小的成就感。
作为一个java工程师来说,对于后端来说,我们需要技术精湛,对于前端来说,我们做到了解就行,但是js一个连接前后端的枢纽,我们还是有必要去熟知的,精通当然更好,现在流行全栈工程师,如果你后端很厉害,js又精通,那么无论是面试还是开发,对于你来说都是非常重要的财富,面试你又很大竞争力,开发你比别人效率高很多,那么你的晋升机会就比较大。总之,如果你有精力就在精通后端的基础上研究一下js,如果精力不足的话,熟知一些常用的js就行了!
(来自一个多年从事java开发的程序员的建议,仅做参考O(∩_∩)O哈哈~)





























