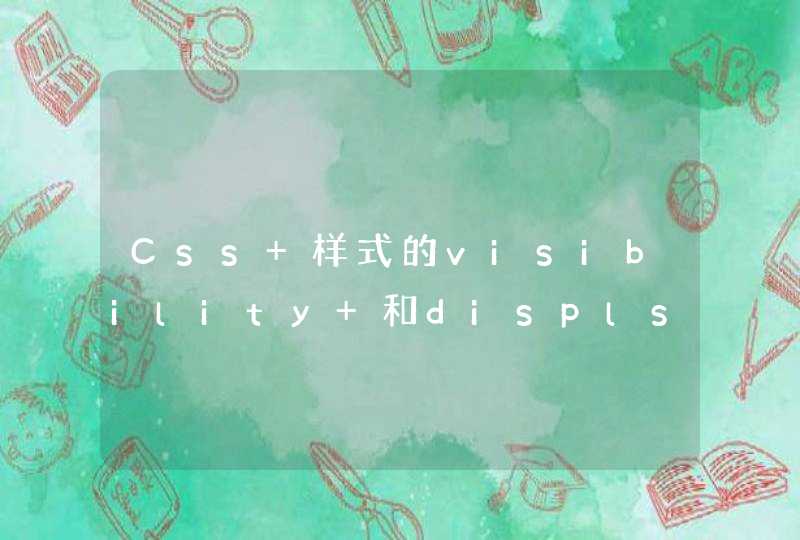#include <string.h>
#define Key_Num 32 //C语言共有32个关键字
#define Len_Min 2 //最短的长度为2
#define Len_Max 8 //最长的长度为8
const char Key[Key_Num][Len_Max+1]={
"auto","break","case","char","const","continue","default","do","double",
"else","enum","extern","float","for","goto","if","int","long","register",
"return","short","signed","sizeof","static","struct","switch","typedef",
"union","unsigned","void","volatile","while"
}
int count[Key_Num]
char input[Len_Max+2]
void CheckKeyWord(){
int i,result
for(i=0i<Key_Numi++){
result=strcmp(input,Key[i])
if(result==0){
count[i]++
break
}
if(result<0)
break
}
}
int main(){
FILE *fi
int i,inQuote
fi=fopen("a.c","r")
if(fi==NULL) return 1
i=inQuote=0
while(fscanf(fi,"%c",&input[i])==1){
if(input[i]=='\\'){//转义符号
fscanf(fi,"%*c")
if(inQuote==0 &&i>=Len_Min &&i<=Len_Max){
input[i]='\0'
CheckKeyWord()
}
i=0
}
else if(input[i]=='\"'){//引号内的关键字不考虑
if(inQuote==0 &&i>=Len_Min &&i<=Len_Max){
input[i]='\0'
CheckKeyWord()
}
i=0
inQuote=1-inQuote
}
else if(input[i]>='a' &&input[i]<='z'){
if(i<=Len_Max)
i++
}
else if(input[i]>='A' &&input[i]<='Z' ||
input[i]>='0' &&input[i]<='9'){
i=Len_Max+1
}
else{
if(inQuote==0 &&i>=Len_Min &&i<=Len_Max){
input[i]='\0'
CheckKeyWord()
}
i=0
}
}
fclose(fi)
fi=fopen("Result.txt","w")
if(fi==NULL) return 1
for(i=0i<Key_Numi++)
fprintf(fi,"%s: %d\n",Key[i],count[i])
fclose(fi)
return 0
}
补充说明:
这是个非常麻烦的问题,需要考虑的问题很多。我不知道你是个什么需求,如果只是自己随便学习一下的话,这个程序大致上可以用了。
除了一些基本情况外,现在已经考虑的问题有:在引号内的关键字不记录,被转义后的引号本身又是不记录。
还有一些没有考虑的问题如,被注释掉的代码不要统计,被#define的代码怎么处理等等。这些问题实现起来有些麻烦,暂时没有考虑。如果你实在有这方面需求的(尤其是注释的代码),我可以试着再改改。
目前关键字匹配上仅仅用了个顺序比较(长度不符合的直接扔掉),如果在效率上有需求的话可以考虑两分比较,或者把关键字根据长度分类,再或者把关键字做成hash表、字典树等复杂数据结构。不过那样的话,一般人就不要指望能读懂了。
暂时先写了这么个程序,还有其它补充的,欢迎交流。
定义一个结构体数组,结构体里面两个元素,一个是该单词的个数,一个是该单词的拼写然后去读文章,以非英文字母作判断,截取单词,然后和结构体数组比较,如果是新单词则放入一个新结构体中,个数设为1,如果该单词已存在,则把该结构体个数+1,最后比较个个结构的个数进行排序即可。