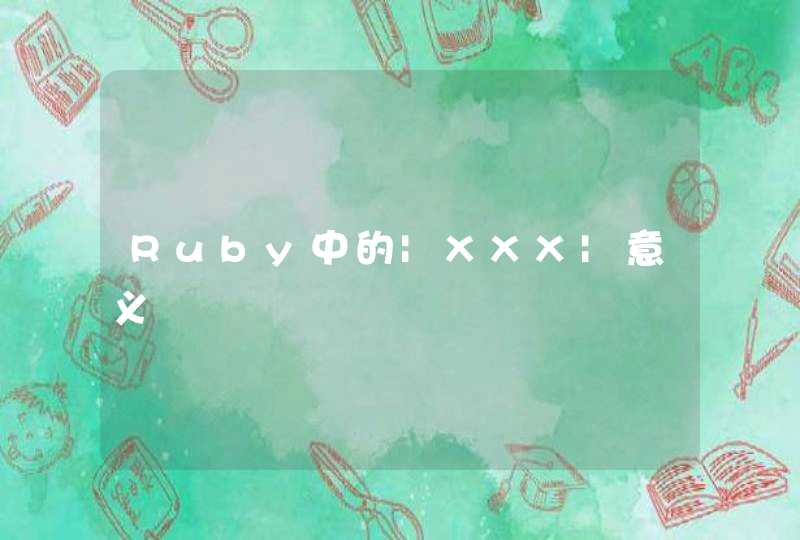的三种方式,第1张")
索引1:切片引用的起始元素位
索引2:切片只引用该元素位之前的元素
例程如下:
在该方法中,我们未指定容量cap,这里的值为5是系统定义的。
在方法一中,可以用arr数组名来操控数组中的元素,也可以通过slice切片来操控数组中的元素。切片是直接引用数组,数组是事先存在的,程序员是可见的。
通过 make 来创建切片,基本语法如下:
make函数第三个参数cap即容量是可选的,如果一定要自己注明的话,要注意保证cap≥len。
用该方法可以 指定切片的大小(len)和容量(cap)
例程如下:
由于未赋值系统默认将元素值置为0,即:
数值类型数组: 默认值为 0
字符串数组: 默认值为 ""
bool数组: 默认值为 false
在方法二中,通过make方式创建的切片对应的数组是由make底层维护,对外不可见,即只能通过slice去访问各个元素。
定义一个切片,直接就指定具体数组,使用原理类似于make的方式。
例程如下:
首先说一下go中的字符串类型: 字符串就是一串固定长度的字符连接起来的字符序列。Go的字符串是由单个字节连接起来的。Go语言的字符串的字节使用UTF-8编码标识Unicode文本。 下面介绍字符串的三种遍历方式,根据实际情况选择即可。 该遍历方式==缺点==:遍历是按照字节遍历,因此如果有中文等非英文字符,就会出现乱码,比如要遍历"abc北京"这个字符串,效果如下: 可见这不是我们想要的效果,根据utf-8中文编码规则,我们要str[3]str[4]str[5]三个字节合起来组成“北”字及 str[6]str[7]str[8]合起来组成“京”字。由此引出下面第二种遍历方法。 该方式是按照字符遍历的,所以不会出现乱码,如下: 运行结果:从图中可以看到第二个汉子“京”的开始下标是6,直接跳过了4和5,可见确实依照utf8编码方式将三个字节组合成了一个汉字,str[3]-str[5]组合成“北”字,str[6]-str[8]组合成了“京”字。 由于下标的不确定性,所以引出了下面的遍历方式。 1 可以先将字符串转成 []rune 切片 2 再用常规方法进行遍历 运行效果:由此可见下标是按1递增的,没有产生跳跃现象。Go语言标准库中提供了sort包对整型,浮点型,字符串型切片进行排序,检查一个切片是否排好序,使用二分法搜索函数在一个有序切片中搜索一个元素等功能。
关于sort包内的函数说明与使用,请查看 https://godoc.org/sort
在这里简单讲几个sort包中常用的函数
在Go语言中,对字符串的排序都是按照字节排序,也就是说在对字符串排序时是区分大小写的。
二分搜索算法
Go语言中提供了一个使用二分搜索算法的sort.Search(size,fn)方法:每次只需要比较㏒₂n个元素,其中n为切片中元素的总数。
sort.Search(size,fn)函数接受两个参数:所处理的切片的长度和一个将目标元素与有序切片的元素相比较的函数,该函数是一个闭包,如果该有序切片是升序排列,那么在判断时使用 有序切片的元素 >= 目标元素。该函数返回一个int值,表示与目标元素相同的切片元素的索引。
在切片中查找出某个与目标字符串相同的元素索引