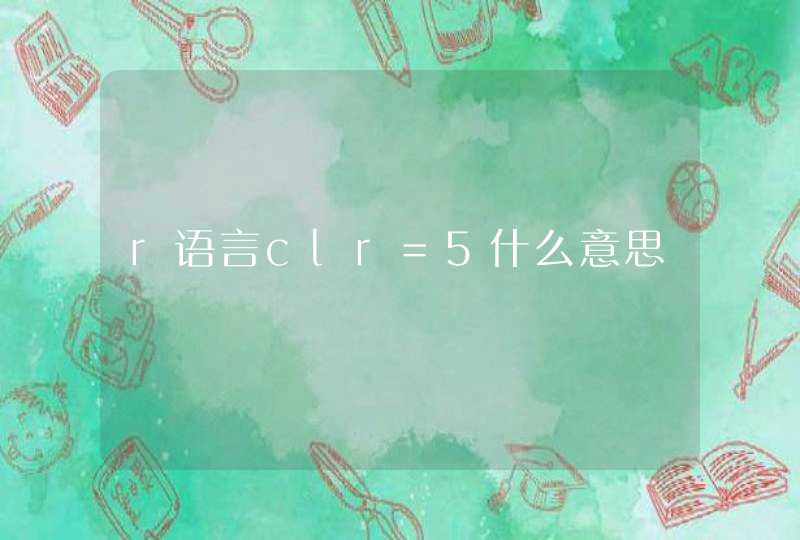围绕 io.Reader/Writer ,有几个常用的实现:
这些实现对于初学者来说其实比较难去记忆,在遇到实际问题的时候更是一脸蒙圈,不知如何是好。下面用实际的场景来举例
encoding/base64 包中:
这个用来做 base64 编码,但是仔细观察发现,它需要一个io.Writer作为输出目标,并用返回的 WriteCloser 的Write方法将结果写入目标,下面是Go官方文档的例子
这个例子是将结果写入到 Stdout ,如果我们希望得到一个字符串呢?观察上面的图,不然发现可以用bytes.Buffer作为目标 io.Writer :
这种场景经常用在基于字节的协议上,比如有一个具有固定长度的结构:
通过一个 []byte 来反序列化得到这个 Protocol ,一种思路是遍历这个 []byte ,然后逐一赋值。其实在 encoding/binary 包中有个方便的方法:
这个方法从一个 io.Reader 中读取字节,并已 order 指定的端模式,来给填充 data (data需要是fixed-sized的结构或者类型)。要用到这个方法首先要有一个 io.Reader ,从上面的图中不难发现,我们可以这么写:
换句话说,我们将一个 []byte 转成了一个 io.Reader 。
反过来,我们需要将 Protocol 序列化得到 []byte ,使用 encoding/binary 包中有个对应的 Write 方法:
通过将 []byte 转成一个 io.Writer 即可:
比如对于常见的基于文本行的 HTTP 协议的读取,我们需要将一个流按照行来读取。本质上,我们需要一个基于缓冲的读写机制(读一些到缓冲,然后遍历缓冲中我们关心的字节或字符)。在Go中有一个 bufio 的包可以实现带缓冲的读写:
这个ReadString方法从 io.Reader 中读取字符串,直到 delim ,就返回 delim 和之前的字符串。如果将 delim 设置为 \n ,相当于按行来读取了:
等价于
原文链接: https://mp.weixin.qq.com/s/gW_3JD52rtRdEqXvyg-lJQ?st=17068D6966C713BFB3B2DFDED2100927184379EBD73179345AA52F7C4770FAB3D9B809F2DDAF6808BD4F4F8FCCC362C468BF936BDB8AD9CD3FD180F6EF4D5D7B47895F771EE88366C0FE695489FF8C80FD9E42300D22D2760A2418189B459A619E1BA2E0BBCA50455B277293988FAAA45BCB1075B07EDAA36B62D6A0CAA886E8045895054068CB955DED17A44781062708DF01AAFCDA746F6C50158B19E5E42A88D02F0ECC5D8BC4EC108AF374A720C972EE1C5D832F23B6B107DC32194F4B0A3840F4739B0806FA6523E2D7A86ABD79A0EFE634158A19905FDB65E67AE97871&vid=1688855587348942&cst=E9F266277367B28319F39975A546E7810FB56065BDFDF61A124CA07F8C69AF9566D809347DAA8BFB56A5A5BFDAC28DAC&deviceid=3f371756-5e39-4325-9fec-0b55bfeb87f5&version=4.0.6.6516&platform=win
所以,通过以上 AlignedBlock 函数分配出来的内存一定是 512 地址对齐的。
有啥缺点吗?
浪费空间嘛。 命名需要 4k 内存,实际分配了 4k+512 。
开源库地址: https://github.com/ncw/directio