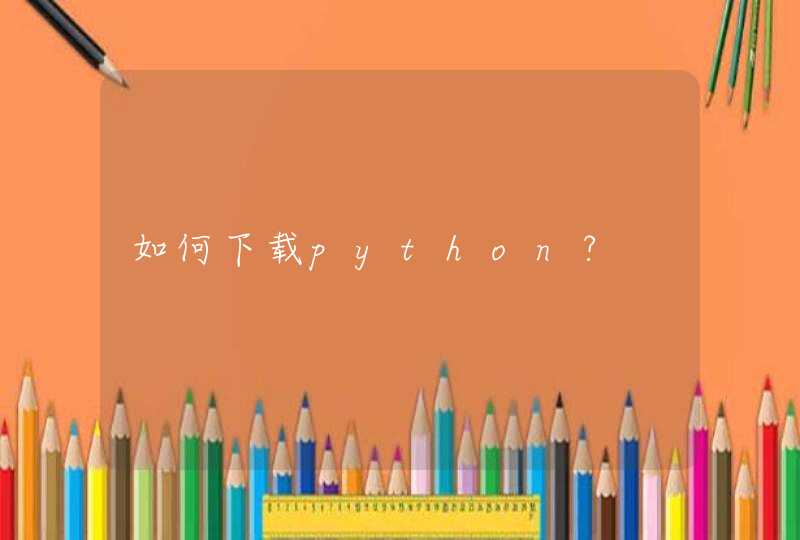x = read.csv("input.csv",header=T)
x=as.dist(x)
hc = hcluster(x,method = "euclidean", link="complete")
labels=hc$labels
height=hc$height
merge=hc$merge
png("hc.png",width = 10,height = 5,res = 300,units="in")
plot(hc)
dev.off()
学习经济学需要熟悉哪些编程语言?1)坛友arthur_2006
处理和分析数据都用得到,最基本的是excel,如果你的VBA用得好的话会有很大的帮助,如果你要分析数据的话,比如你要建模那么SAS还是不错的,不过比较难掌握如果你没有语言方面的基础,其他还有很多软件也能做得到。很多银行证券期货企业都使用的是oracle或者DB2,一些小企业可能使用的是SQL, 所以如果想在这方面发展就要掌握数据库的知识,毕竟金融和计算机兼备的人才还是稀缺的,而且国内很多行业都是用的是这几大数据库比如电信医疗航空等等,不会分析金融数据恐怕称不上什么金融专家吧,至于你分析得准还是不准那就要看你的金融知识掌握的程度啦,尤其是投资专业的学生学习一些这方面的知识是必要的,很多人是应用金融学专业的偏向于财务,那就去考考CFA,ACCA什么的,也没必要在这上面花费太多精力而且工作中很可能用不到的,金融数学金融工程精算专业的同学花点时间研究一下还是很有必要的,总而言之一句话,首先要看你的兴趣再就是你的专业和发展方向。
2)编程爱好者任坤
做统计和计量的话,想要跟当今的国际学术界接轨,最好学R,至少我所知道的目前美国的统计学术界被R占领的趋势很明显了。
如果只是做简单地回归随便解读一下,那随便选个傻瓜软件就可以了。如果只是应用现成的成熟的计量模型来做实证研究,那么傻瓜软件一般也就可以了。如果要以统计、计量为研究领域或者专业领域,那么编程性的东西是少不了的,即使是做实证如果涉及较为复杂的数据结构,懂编程也能帮你大幅提高生产力。另外,R的社区比较活跃,能够较好地跟上前沿。
如果涉及到处理较大的数据,一种办法是用SAS,如果不想用SAS可以学数据库方面的东西,比如把数据放在SQLite数据库中然后用{RSQLite}访问数据库,或者用{sqldf}通过SQL操作环境中的data frame。
如果觉得执行某项任务R单核速度慢,那么可以使用{parallel}或者{parallelMap}做并行计算,也可以利用云计算来处理数据。
如果涉及到其他社区的东西在R社区中没有实现,例如Java的东西,可以用{rJava}来调用Java的对象,不过速度有些慢。
比较好的办法是我在想从事数据分析工作,学什么软件或语言最好? 提到的F#函数式编程语言,用RProvider可以直接调用R,用JavaProvider直接调用Jar打包的Java程序,用PythonProvider(即将发布)直接调用Python程序,等等,很容易将各大社区的资源整合在一起使用。
目前我在GitHub上面弄一个通过R学习统计、计量、非参、数据可视化、数据库的repo: renkun-ken/learnR on GitHub ,虽然目前还没什么内容,不过可以跟踪一下。
以上说得都是经济学相关的统计和计量方面所需要的编程。事实上统计和计量所需的「编程」较为简单,基本也就是处理数据、应用已经提供的计量模型,更多需要编程的是:一、如果涉及较为前沿的计量模型,可能还需要自己实现;二、一些蒙特卡罗模拟需要一些编程。
从经济学相关的一些新型领域来说,计算经济学(Computational Economics)、计算统计学(Computational Statistics)以及计算计量学(Computational Econometrics)则需要较强的编程能力,包括算法实现、算法分析等等。举个例子,计算经济学中目前做的一块研究是Agent-based computational finance,就是建立一个模拟的金融市场,里面有几种资产,每种资产的基本面由随机的红利决定,里面有许多遵循各种逻辑的投资者,投资者对于红利发放持有的信念不同,因而从各自的逻辑触发的交易行为不同。在一个复式竞价(double auction)的交易市场中,什么样的投资者组成或者行为方式、什么样的记忆长短,能够最大程度地复制出我们在现实金融市场中观测到的资产价格或者资产收益率规律,例如资产收益率尖峰肥尾、不对称性。此时,研究者就需要较扎实的金融知识来设计一个不过于简单而又不过于复杂的模拟金融市场,也需要相应的编程能力把模型用程序语言编写出来。这中间会设计许多编程技术,例如数据库(有时要跟踪许多变量,例如投资者现金流动、财富分布)、并行计算(CPU多核并行、多进程并行、集群上的并行甚至GPU计算)等等。这方面的研究从1990s年代才开始。
3)知乎网友Jichun Si
计量经济学也有很多小的门类,请对号入座。有很多软件,Stata, matlab, R, SAS是相对来说用的比较多的。
如果是做应用计量(特别是横截面数据、面板数据),Stata是不二之选,因为不管是管理数据还是跑回归,实在太太太方便了。现在主流期刊的应用微观计量文章里面能用到的模型stata几乎都有,而且其中的绝大多数都是用stata做的。而且最大的优点是,简单!
如果做应用的时间序列,Eviews似乎是一个不错的选择。但是我一般不做这方面,也不是很有发言权。
如果做理论计量,stata eviews是没有现成的包的,而且即便Stata可以编程,可编程能力也是很差的,而且不稳健。所以懂R和Matlab就非常顺手。当然也可以用Python,最近Sargent就写了本用Python做计量的书。还有一个Julia,是这三种语言的混合,但是速度快很多,缺点是太过于小众。
如果对速度要求高,特别是金融计量很多对速度有要求的,可以考虑C、Fortran等语言。C和Fortran肯定是最快的。还有一个叫做OX的,速度快,但是也很小众。但是这些语言的缺点是学习难度比较高,开发时间比较慢。Julia据说速度堪比C,而且语法特别像Matlab、Python(意味着容易学习),但是处于刚起步阶段,用的人太少了。
如果是金融计量领域,强烈建议学会SAS。SAS是最权威,速度也很快,当然最大的问题是昂贵,而且可编程能力不是多么好。但是金融里面数据量都非常非常非常大,一般的软件都瘫的时候,SAS就派上用场了。
像我自己,做应用的时候都是用stata整理数据,能用stata的坚决不用其他软件。但是因为有的时候做一些理论计量的工作,所以matlab也是必不可少的。我也在学习Julia,因为matlab的速度实在太慢。Python我一般不用来做科学计算,用的人不多,而且速度慢,一般是用来抓数据的。
最后还是补充一点吧,为什么我推荐matlab而不是其他的软件,也是有道理的。很多模型,比如空间计量模型(spatial econometrics)、贝叶斯估计、以及宏观计量里面的DSGE model、SVAR等模型,在stata、Eviews里面都是没有什么现成的东西可以用的,但是matlab提供了丰富的包,比如Dynare就是基于Matlab的,还有LeSage的空间计量软件包等等,也是基于matlab的。所以几乎你想用的模型matlab里面都能找到codes然后直接用。就算没有,你自己在matlab里面写,也不是什么难事。
最后想起一句话来,关于这些软件的选择(stata除外,因为stata在应用计量领域的地位是几乎不可替代的)可以用两句话来概括:如果你自己的时间比计算机的时间宝贵的话,学习matlab、R、甚至Python、Julia是最合适的,如果计算机的时间比你的时间宝贵的话,学习C、Fortran是必须的。当然除非你的工作非常特殊(比如一些大型的结构模型的估计),一般来说,还是自己的时间更宝贵一点。
综上,做应用和做理论是不可能用一种软件解决的,建议根据自己的方向进行挑选。我觉着stata、matlab是比较推荐的,一个方便,一个灵活,都很强大,而且学习难度都不大,用的人都很多,交流起来相当方便。
4)网友张真实
数据,简单的用excel,直观,方便。复杂一些的…excel最多可以有6万多行,你确定你需要从那么大量的数据开始“学经济学么?
复杂的用R,各种模型,算法,实现,基本上R都有对应的软件包了,下载下来直接用即可,多读文档多练多用,半年左右就可以抛开excel直接用R作实战了。我博士论文全部回归和输出都是用R的,现在写的论文也都用它。替代品是Stata。也很好,但如果你和我一样是从0开始,那么强烈建议选R。
R的一个不足是没法作符号运算,这个免费的解决方案有python搭配scipy numpy等几个包,不过建议你用mathematica,它的符号计算功能最强大,输出格式也最好。你可以找个jacobian矩阵搞一下符号计算,比较一下结果就知道了。
Python这东西,熟悉了R之后,发现有功能是R实现不了的,到时候有实际需求了,再学也不迟。不是立刻就需要的。
此外,所有经济学研究(我是指empirics类型的,具体意思你懂的),都要会用latex,可以把它看做是一门编程语言。在word里排数学公式,用不了多久你就会疯掉。R中可以用ggplot2来绘图,输出到tex中。普通数据表用xtable包输出到tex,回归结果用stargazer输出到tex,都很方便。
5)网友bayes
首先要说的是R,绝对是目前国外学术界的主流,统计系基本除R以外没有其他了,计量作为和统计相关的方向,R也在逐渐渗透。所以推荐学习。
顺便说一句,R的学习曲线是比较陡峭的,所以我不太建议零基础的人从R开始,否则挫折感会比较强烈。而python会略好,所以我建议从python开始。
python并非是专用于统计或者计量的软件,而是一种非常流行的通用编程语言。经过多年发展,库也非常齐备。我试用过numpy,scipy和pandas等库,与其他通用编程语言相比,算是相当好用,不过个人感觉还是比不上R,比如画图,
ggplot2真心是神一般的存在,python的库还是略逊一筹。但是,除了数据处理之外,python可以干的事情太多了,也太牛了。我们主要要用到的,比如网页采集数据,需要正则表达式,解析网页等等。这些方面python就比R有优势多了。
当然,从趋势来看,未来似乎python比R更优。R是一群统计学家在编程序,python是一群计算机专家在争取搞数据处理。似乎python的基础更扎实。个人观点,仅供参考。
stata我认为是除了R以外最好的计量软件了,我两者均用过数年数个项目,但是依然感觉R更好用,整理和处理数据更方便。所以即使在楼上诸位所提到的微观计量领域,我依然更喜欢R。
除此以外spss,或者eviews等,感觉管理类学生用的更多,功能比较受限,不太推荐。这里不赘述。上述的几个软件,还有个问题,在于都是收费的,考虑到未来知识产权的保护,还是用免费的略靠谱。
R的主要缺点有两个:
1,面对大数据乏力。这方面sas确实有优势,但是不得不说,sas的语法太反人类了,完全接受不能。面对这个问题,我要说的是,你得看问题有多大。以我的经验,经济里面的数据量似乎还不足以超过R的处理上限很多。可能金融的高频数据会比较大,我个人没啥经验,如果遇到再补充。我尝试过10g的数据,最简单的办法,不是学sas,而是买16g的内存。:)以现在的内存价格,我觉得32g以下的问题不大。
2,性能不足。这方面python也有同样的问题,最好的解决方案是混合c/c++,不过这个就是无底洞了,耗时极多,都不见得能学好。建议的方法,还是买硬件,这个最简单。:)当然用并行包等,也是解决方法之一,我尝试过几次用机房的多台机器做集群,不是太成功。求高人指点。
上面诸位还提到过几个软件,我也略微说一下自己知道的一些软件的看法:
matlab:好东西,关键还是性能问题,同样可以靠c/c++来解决。但是我不喜欢比较大的软件,为了求个均值方差,等它启动就占了5分钟。。。
julia:好东西X2,目前关注中,可能还比较年轻,导致配套的库略少,不过看好未来发展,主要是吸取了matlab,python和c/c++的有点,写的快,运算的也快,未来看涨,紧密关注。
最后提一下函数式编程,是个好东西,但是不看好纯粹函数式编程的未来。它体现了一种颇先进的编程思想,但是在实际工作中,往往性能方面的问题较大。要解决这个问题,还是的混合函数式编程和其他方式,但这就是python,R等软件已经实现的方式,似乎又没有必要专门去学其他的函数式编程了。
6)上海财经大学博士 荣健欣
Stata微观计量中应用极多,主要是直接输命令回归,需要编程的地方不多。
至于编程,推荐R、Python.
R是非常好的统计分析软件,在计量经济学中的应用可以见Econometrics in R, Applied Econometrics with R Time Series Analysis with Applications in R这几本书
Python用来抓数据很好,并且有数学计算包SciPy可以部分替代Matlab之类科学计算的功能。
7)知乎网友justin
本科经济统计学,由于学校奇葩的课程设置,我们分别使用过:
EViews:计量经济学,时序和多元统计。
Stata:计量经济学。
SPSS:专门开的一门课,这个巨汗,权当复习了一遍统计学。
Excel:大一的统计入门课使用的,这个也巨坑,就是简单的函数使用,一点没有涉及VBA。
Matlab:这个没有专门的课,是上完了C语言程序设计以后副产品,后来接触了R和Mathematica就基本抛弃了它。
R/S-Plus:在回归分析的时候使用了S-Plus,不过那时候我已经使用R语言很久了,而且S-Plus基本兼容,所以没有使用过S-Plus。
Minitab:质量控制课程上用的,基本的统计加上一些实验设计。
SAS:这个在实验室中自学过几次,直接被其奇葩的语法雷到了,据说我们学校的研究生有专门的SAS课程(类似于本科的SPSS课程),呵呵了~
我们系的妹(xue)纸(ba)就曾经抱怨说使用的软件太多了,完全被逼疯的感觉,还给我们亲爱的系主任提过意见。作为学渣也就这个问题问过系主任,她的意思是不同的软件在处理不同的数据时候是各有所长的,而且你们课程还是蛮轻松的,就多学点吧,另外不同的老师有不同的软件使用爱好,上课使用不同的软件是必然的。
学习经济学的同学,Excel和SPSS,EViews(或者Stata)就蛮好的了,Stata和EViews都可以写一些程序的,SPSS的界面化操作也是很友好的。本人使用的R,在上各种课中也都会在学了那些软件后再使用R来实现(其实绝大多数时候R都已经有现成的包了,我也大多是直接使用),R还是很不错的,推荐。
很多前辈也提出了,经济学学生学习编程适可而止就好了,要不然就是一条不归路啊,面临着彻底转行的危险,本人就是一枚反面例子(泪~。所以什么Python啊,C++啊,Julia啊就不要接触了。
课程采用Ruey S. Tsay的《金融数据分析导论:基于R语言》(Tsay 2013 ) (An Introduction to Analysis of Financial Data with R)作为主要教材之一。
时间序列的线性模型,包括:
股价序列呈现缓慢的、非单调的上升趋势, 局部又有短暂的波动。
可口可乐公司每季度发布的每股盈利数据。 读入:
时间序列图:
序列仍体现出缓慢的、非单调的上升趋势,又有明显的每年的周期变化(称为季节性), 还有短期的波动。
下面用基本R的 plot() 作图并用不同颜色标出不同季节。
现在可以看出,每年一般冬季和春季最低, 夏季最高,秋季介于夏季和冬季之间。
收益率在0上下波动,除了个别时候基本在某个波动范围之内。
用xts包的 plot() 函数作图:
聚焦到2004年的数据:
红色是6月期国债利率, 黑色是3月期国债。 一般6月期高, 但是有些时期3月期超过了6月期,如1980年:
如图标普500月收益率那样的收益率数据基本呈现出在一个水平线(一般是0)上下波动, 且波动范围基本不变。 这样的表现是时间序列“弱平稳序列”的表现。
弱平稳需要一阶矩和二阶矩有限。某些分布是没有有限的二阶矩的,比如柯西分布, 这样的分布就不适用传统的线性时间序列理论。
稍后给出弱平稳的理论定义。
如图2可口可乐季度盈利这样的价格序列则呈现出水平的上下起伏, 如果分成几段平均的话, 各段的平均值差距较大。 这体现出非平稳的特性。
以下为一堆公式推导,具体查看: http://www.math.pku.edu.cn/teachers/lidf/course/fts/ftsnotes/html/_ftsnotes/fts-tslin.html#fig:tslin-intro-sp02
时间序列
自协方差函数
弱平稳序列
图6 是IBM股票月度简单收益率对标普500收益率的散点图。 从图中看出, 两者有明显的正向相关关系。
对于不独立的样本, 比如时间序列样本, 也可以计算相关系数, 其估计合理性需要一些模型假设。
对于联合分布非正态的情况, 有时相关系数不能很好地反映X和Y的正向或者负向的相关。 斯皮尔曼(Spearman)相关系数是计算X的样本的秩(名次)与Y的样本的秩之间的相关系数, 也称为Spearman rank correlation。
另一种常用的非参数相关系数是肯德尔tau(Kendall’s )系数, 反映了一致数对和非一致数对之间的差别。
即两个观测的分量次序一致的概率减去分量次序相反的概率。 一致的概率越大,说明两个的正向相关性越强。
对IBM收益率与标普收益率数据计算这三种相关系数:
自相关函数 (Autocorrelation function, ACF)参见 (何书元 2003 ) P.131 §4.2的例2.1。 原始文献: MAURICE STEVENSON BARTLETT, On the Theoretical Specification and Sampling Properties of Auto-Correlated Time Series, Journal of the Royal Statistical Society (Supplement) 8 (1946), pp. 24-41.
在基本R软件中, acf(x) 可以估计时间序列 x 的自相关函数并对其前面若干项画图。
例:CRSP的第10分位组合的月对数收益率, 1967-1到2009-12。 第10分位组合是NYSE、AMEX、NASDAQ市值最小的10%股票组成的投资组合, 每年都重新调整。
图6: CRSP第10分位组合月对数收益率
用 acf() 作时间序列的自相关函数图:
acf() 的返回值是一个列表,其中 lag 相当于, acf 相当于。 用 plot=FALSE 取消默认的图形输出。
有研究者认为小市值股票倾向于在每年的一月份有正的收益率。
为此,用对的检验来验证。 如果一月份有取正值的倾向, 则相隔12个月的值会有正相关。
计算统计量的值,检验p值:
值小于0.05, 这个检验的结果支持一月份效应的存在性。
Ljung和Box(Ljung and Box 1978 )对Box和Pierce(Box and Pierce 1970 )提出了混成统计量(Portmanteau statistic)
检验方法进行了改进
在R软件中, Box.test(x, type="Ljung-Box") 执行Ljung-Box白噪声检验。 Box.test(x, type="Box-Pierce") 执行Box-Pierce混成检验。 用 fitdf= 指定要减去的自由度个数。
检验IBM股票月收益率是否白噪声。
考虑IBM股票从1926-01到2011-09的月度收益率数据, 简单收益率和对数收益率分别考虑。
读入数据:
读入的是简单收益率的月度数据。 作ACF图:
从ACF来看月度简单收益率是白噪声。
作Ljung-Box白噪声检验, 分别取和:
在0.05水平下均不拒绝零假设, 支持IBM月度简单收益率是白噪声的零假设。
从简单收益率计算对数收益率, 并进行LB白噪声检验:
在0.05水平下不拒绝零假设。
Box-Pierce检验和Ljung-Box检验受到取值的影响, 建议采用, 且序列为季度、月度这样的周期序列时, 应取为周期的整数倍。
对CRSP最低10分位的资产组合的月简单收益率作白噪声检验。
此组合的收益率序列的ACF:
针对和作Ljung-Box白噪声检验:
在0.05水平下均拒绝零假设, 认为CRSP最低10分位的投资组合的月度简单收益率不是白噪声。
有效市场假设认为收益率是不可预测的, 也就不会有非零的自相关。 但是,股价的决定方式和指数收益率的计算方式等可能会导致在观测到的收益率序列中有自相关性。 高频金融数据中很常见自相关性。
常见的白噪声检验还有TREVOR S. BREUSCH (1978) 和LESLIE G. GODFREY (1978)提出的拉格朗日乘子法检验(LM检验)。 零假设为白噪声, 对立假设为AR、MA或者ARMA。 参见:
设是独立同分布的二阶矩有限的随机变量, 称为独立同分布白噪声(white noise)。 最常用的白噪声一般假设均值为零。 如果独立同分布, 称为高斯(Gaussian)白噪声或正态白噪声。
白噪声序列的自相关函数为零(除外)。
实际应用中如果样本自相关函数近似为零 (ACF图中都位于控制线之内或基本不超出控制线), 则可认为该序列是白噪声的样本。
如:IBM月度收益率可以认为是白噪声(见例 3.3 ); CRSP最低10分位投资组合月度收益率不是白噪声(见例 3.4 )。
不是所有的弱平稳时间序列都有这样的性质。 非平稳序列更是不需要满足这些性质。
公式就不赘述
如果从时间序列的一条轨道就可以推断出它的所有有限维分布, 就称其为严平稳遍历的。 这里不给出遍历性的严格定义, 仅给出一些严平稳遍历的充分条件。 可以证明, 宽平稳的正态时间序列是严平稳遍历的, 由零均值独立同分布白噪声产生的线性序列是严平稳遍历的。
Tsay, Ruey S. 2013. 金融数据分析导论:基于R语言 . 机械工业出版社.
何书元. 2003. 应用时间序列分析 . 北京大学出版社.
Box, GEP, and D. Pierce. 1970. “Distribution of Residual Autocorelations in Autoregressive-Integrated Moving Average Time Series Models.” J. of American Stat. Assoc. 65: 1509–26.
Ljung, G., and GEP Box. 1978. “On a Measure of Lack of Fit in Time Series Models.” Biometrika 66: 67–72.
参考学习资料: http://www.math.pku.edu.cn/teachers/lidf/course/fts/ftsnotes/html/_ftsnotes/fts-tslin.html#fig:tslin-intro-sp02