




































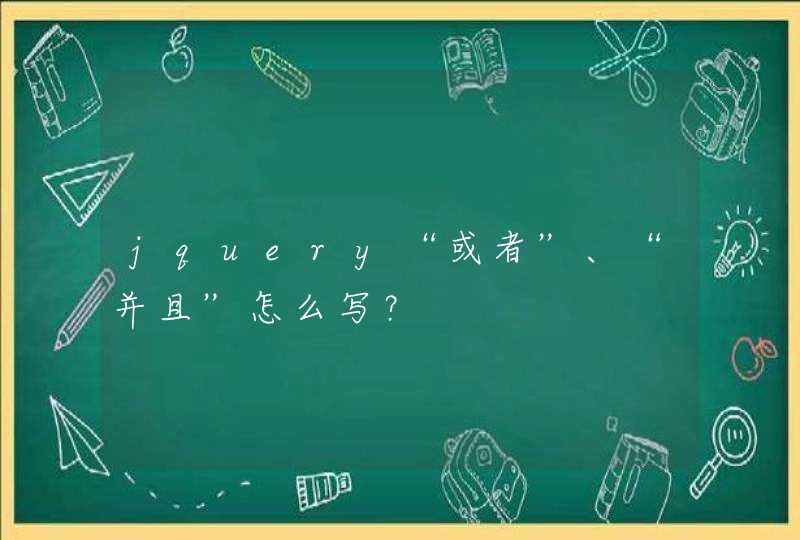



方法1:把中文字替换成两个字母。然后计算长度。
方法2:直接判断中文,长度+2。
运用的方法大同小异。都是通过正则表达式,写unicode编码。
方法1中
[\u4e00-\u9fa5]:匹配中文字符
[^\x0000-\x00ff]:匹配双字节字符(包括中文字)
正则表达示 /[\u4e00-\u9fa5]/g 的 g 必须要,global,全部都要检查的意思。没有的话输出的是(2333aa哈)
方法2中的函数
扩展:
JAVA有一个public String(byte bytes[], Charset charset)函数可以用指定字节数组和编码来构造字符串。一个public byte[] getBytes(Charset charset)函数把字符串按指定编码来得到字节数组。可以用这两个函数来实现编码转换。下面是一个简单的例子,注意一下例子中的文字本身的编码,最好在自己的环境中用gb2312重新输入,不然可能是乱码。当然转换后输出肯定有一个是乱码,也肯能都是乱码。根据你的编辑器的编码格式有关。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class EncodingTest
{
public static void main(String[] args)
{
try
{
String gb = new String("国标2312".getBytes(),"gb2312")
System.out.println(gb)
byte [] b = gb.getBytes("gb2312")
String ios = new String(b,"ISO-8859-1")
System.out.println(ios)
} catch (UnsupportedEncodingException e)
{
e.printStackTrace()
}
}
}




























