























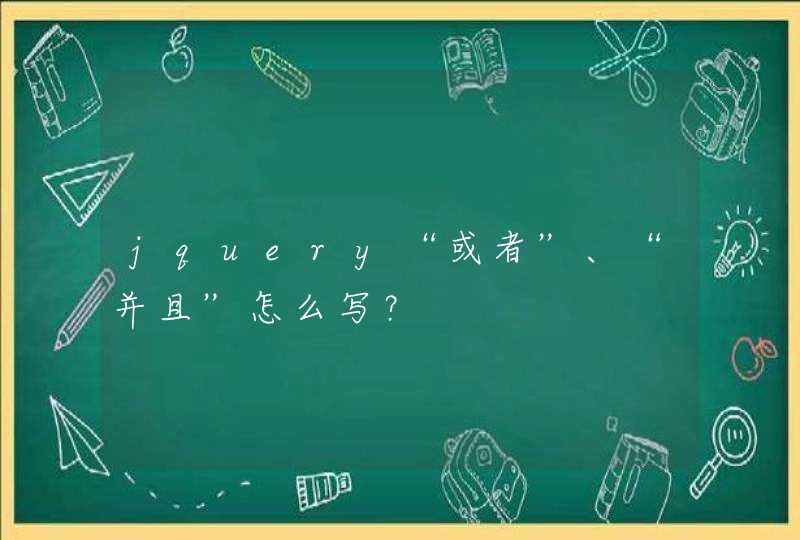
















string
matchString =
@"<a[^>]+href=\s*(?:'(?<href>[^']+)'|""(?<href>[^""]+)""|(?<href>[^>\s]+))\s*[^>]*>"
2,得到网页的标题:
string matchString = @"<title>(?<title>.*)</title>"
3,去掉网页中的所有的html标记:
string temp = Regex.Replace(html, "<[^>]*>", "")//html是一个要去除html标记的文档
4, string matchString = @"<title>([\S\s\t]*?)</title>"
5,js去掉所有html标记的函数:
function delHtmlTag(str)
{
return str.replace(/<[^>]+>/g,"")//去掉所有的html标记
}
你可以利用正则表达式来剔除这些标签,也就是将所有的html类的标签都替换为空即可:
//去除HTML 标签str = str.replace(/<\/?[^>]*>/g,'')
是连p以外的标签的内容都不要么?
如果是的话,可以反过来想,只要匹配所有p标签以及其以内的内容即可,那么可以这么写
var re = new RegExp("<p>\\w*</p>","g")result = str.match(re)
str是你所需要进行匹配的字符串,如果是页面全部,就获取body下所有的内容就好
result是一个数组,而每一个元素就是你匹配对象中的p标签以及其内容




























