



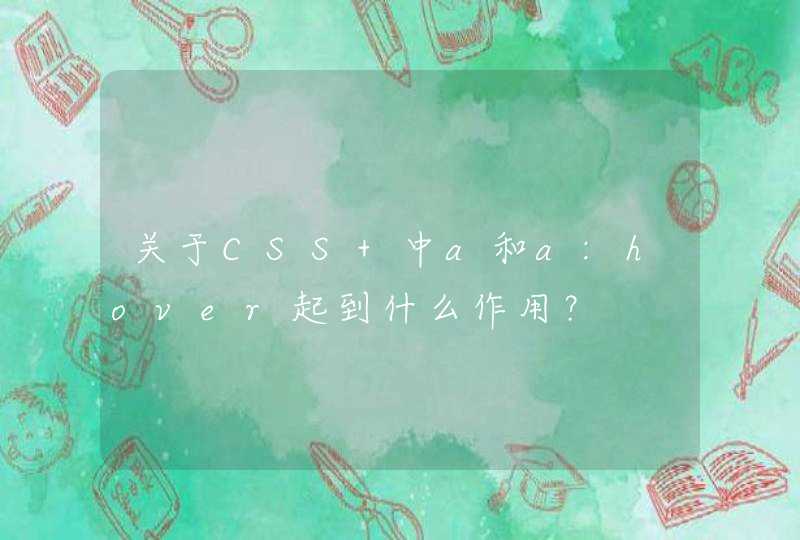



































代码如下:
function readHTML(){
$.ajax({
async:false,
url : "aa.html“,
success : function(result){
alert(result)
}
})
}
async:false,这个是做与其他的js同步的,若为true或不填将会先运行同级别的其它代码,也就是说这里的result为空,只有其它代码执行完毕后才会运行里面的东西,result才会有值,这通常不是所需要的
表达的可能不是很清楚,自己做个测试就明了了,这是介绍此属性的一个详细的例子:http://www.cnblogs.com/wlmemail/archive/2010/06/22/1762765.html
注:这是使用的jQuery
使用js的话是下面的代码
复制代码 代码如下:
var xmlhttp
if (window.XMLHttpRequest) { // 兼容 IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest()
}
else { // 兼容IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP")
}
xmlhttp.onreadystatechange = function() {
if (xmlhttp.readyState == 4 &&xmlhttp.status == 200) {
document.getElementById("myDiv").innerHTML = xmlhttp.responseText
}
}
xmlhttp.open("GET", "aa.html", true)
xmlhttp.send()
myDiv是你输出的位置,这个是定义在了页面上的一个div
http://www.jb51.net/article/41454.htm
嗯嗯、HTML是用来做网站的一种语言哈、这样吧、你打开一个网页、然后再网页任何一个地方点击鼠标右键、然后选择“查看源文件”、点击过后将以记事本的形式打开、里面的就全是HTML代码哈、看看吧、希望对你有所帮助!至于怎么使用这个就有专门的教程了哈、你到百度文库里面找找教程嘛、






















