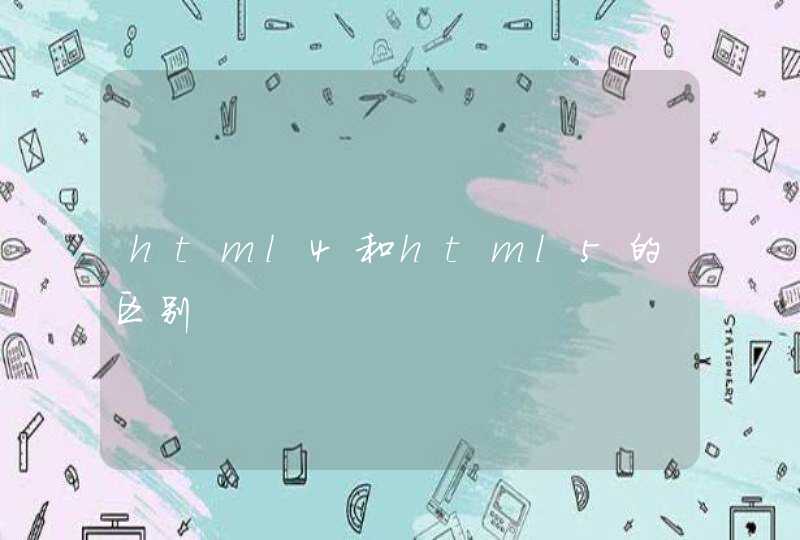try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10)
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true)
webClient.getOptions().setCssEnabled(false)
webClient.setAjaxController(new NicelyResynchronizingAjaxController())
//webClient.getOptions().setTimeout(50000)
webClient.getOptions().setThrowExceptionOnScriptError(false)
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url)
System.out.println("为了获取js执行的数据 线程开始沉睡等待")
Thread.sleep(3000)//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡")
String html = rootPage.asText()
System.out.println(html)
} catch (Exception e) {
}