

















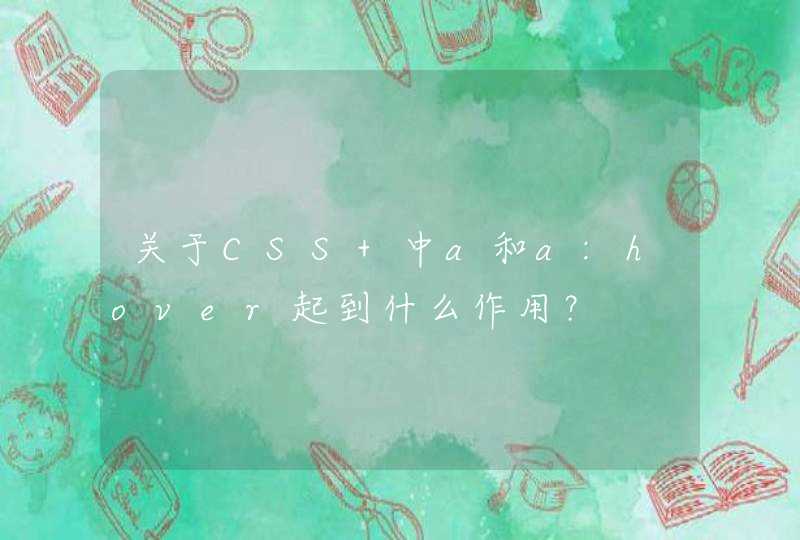






















string
matchString =
@"<a[^>]+href=\s*(?:'(?<href>[^']+)'|""(?<href>[^""]+)""|(?<href>[^>\s]+))\s*[^>]*>"
2,得到网页的标题:
string matchString = @"<title>(?<title>.*)</title>"
3,去掉网页中的所有的html标记:
string temp = Regex.Replace(html, "<[^>]*>", "")//html是一个要去除html标记的文档
4, string matchString = @"<title>([\S\s\t]*?)</title>"
5,js去掉所有html标记的函数:
function delHtmlTag(str)
{
return str.replace(/<[^>]+>/g,"")//去掉所有的html标记
}
你可以利用正则表达式来剔除这些标签,也就是将所有的html类的标签都替换为空即可:
//去除HTML 标签str = str.replace(/<\/?[^>]*>/g,'')
// 这里为了方便使用jQuery// 移除使用tag类的div标记下的strong标记下a标记下没有子元素(链接为空)的节点元素
jQuery('div.tag strong a:empty').parent().remove()





























