











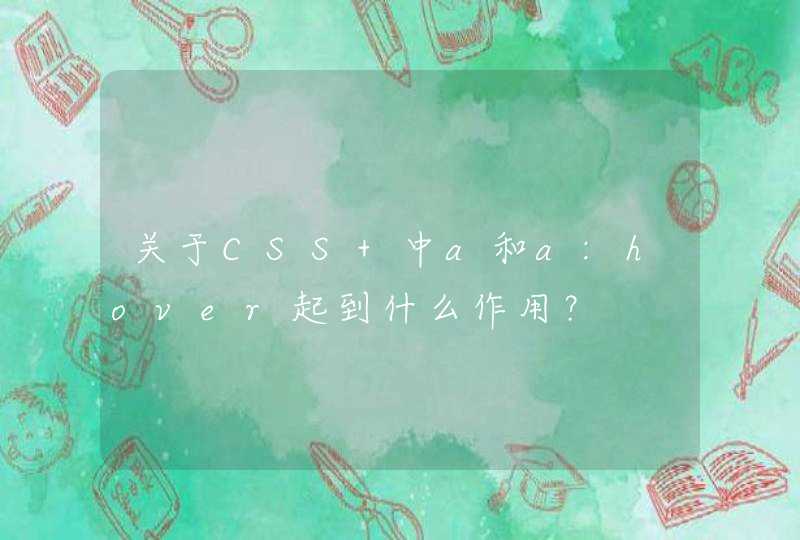




























浏览器渲染引擎从网络层取得请求的文档,一般情况下文档会分成 8KB 大小的分块传输。
HTML 解析器的主要工作是对 HTML 文档进行解析,生成解析树。
解析树是以 DOM 元素以及属性为节点的树。DOM 是 文档对象模型(Document Object Model) 的缩写,它是 HTML 文档的对象表示,同时也是 HTML 元素面向外部(如 JavaScript)的接口。树的根部是 Document 对象。整个 DOM 和 HTML 文档几乎是一对一的关系。
解析算法
HTML 不能使用常见的自顶向下或自底向上方法来进行分析。主要原因有以下几点:
由于不能使用常用的解析技术,浏览器创造了专门用于解析 HTML 的解析器。解析算法在 HTML5 标准规范中有详细介绍,算法主要包含了两个阶段: 标记化(tokenization)和树的构建 。
解析结束之后
浏览器开始加载网页的外部资源(CSS,图像,JavaScript 文件等)。
此时浏览器把文档标记为 可交互的(interactive) ,浏览器开始解析处于 推迟(deferred) 模式的脚本,也就是那些需要在文档解析完毕之后再执行的脚本。之后文档的状态会变为 完成(complete) ,浏览器会触发 加载(load) 事件。
注意解析 HTML 网页时永远不会出现 无效语法(Invalid Syntax) 错误,浏览器会修复所有错误内容,然后继续解析。
将打开方式设定为IE浏览器
在文件上右击,并移到出现的右键菜单中的“打开方式”,再在出现的小菜单中进行选择,若没有IE浏览器这个选择,就点击这个小菜单中的“选择默认程序”进行选择,或“浏览“来选择IE浏览器。
此方法是一次性的,下次打开方式就不是IE浏览器了。
在文件上右击,并点击右键菜单的属性,在弹出的对话框的“打开方式”一栏中点击“更改”进行选择,或“浏览“来选择IE浏览器。
此方法是永久的,下次打开方式还是IE浏览器。
将次文件拖到IE浏览器的图标上就可以打开。
提示:很多文件不能用浏览器打开,或出现乱码等。





























