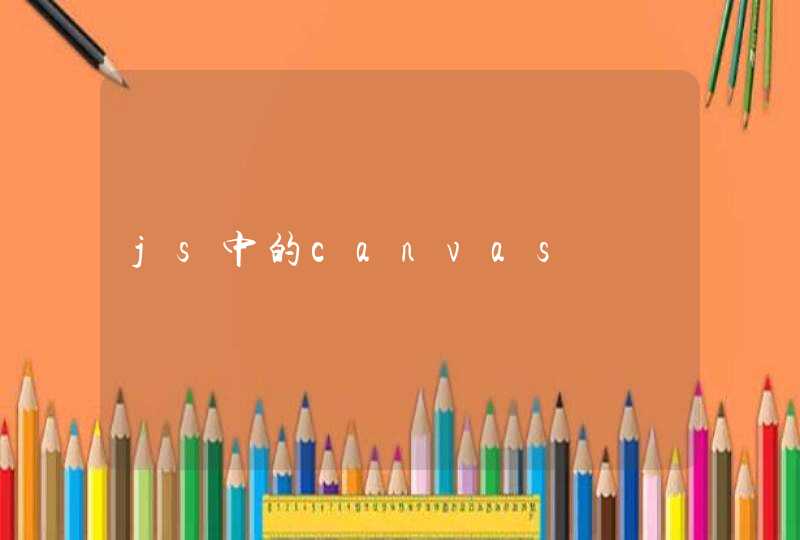1)距离和相似系数
r语言中使用dist(x, method = "euclidean",diag = FALSE, upper = FALSE, p = 2) 来计算距离。其中x是样本矩阵或者数据框。method表示计算哪种距离。method的取值有:
euclidean 欧几里德距离,就是平方再开方。
maximum 切比雪夫距离
manhattan 绝对值距离
canberra Lance 距离
minkowski 明科夫斯基距离,使用时要指定p值
binary 定性变量距离.
定性变量距离: 记m个项目里面的 0:0配对数为m0 ,1:1配对数为m1,不能配对数为m2,距离=m1/(m1+m2)
diag 为TRUE的时候给出对角线上的距离。upper为TURE的时候给出上三角矩阵上的值。
r语言中使用scale(x, center = TRUE, scale = TRUE) 对数据矩阵做中心化和标准化变换。
如只中心化 scale(x,scale=F) ,
r语言中使用sweep(x, MARGIN, STATS, FUN="-", ...) 对矩阵进行运算。MARGIN为1,表示行的方向上进行运算,为2表示列的方向上运算。STATS是运算的参数。FUN为运算函数,默认是减法。下面利用sweep对矩阵x进行极差标准化变换
?
1
2
3
>center <-sweep(x, 2, apply(x, 2, mean)) #在列的方向上减去均值。
>R <-apply(x, 2, max) -apply(x,2,min) #算出极差,即列上的最大值-最小值
>x_star <-sweep(center, 2, R, "/") #把减去均值后的矩阵在列的方向上除以极差向量
?
1
2
3
>center <-sweep(x, 2, apply(x, 2, min)) #极差正规化变换
>R <-apply(x, 2, max) -apply(x,2,min)
>x_star <-sweep(center, 2, R, "/")
有时候我们不是对样本进行分类,而是对变量进行分类。这时候,我们不计算距离,而是计算变量间的相似系数。常用的有夹角和相关系数。
r语言计算两向量的夹角余弦:
?
1
2
y <-scale(x, center =F, scale =T)/sqrt(nrow(x)-1)
C <-t(y) %*%y
相关系数用cor函数
2)层次聚类法
层次聚类法。先计算样本之间的距离。每次将距离最近的点合并到同一个类。然后,再计算类与类之间的距离,将距离最近的类合并为一个大类。不停的合并,直到合成了一个类。其中类与类的距离的计算方法有:最短距离法,最长距离法,中间距离法,类平均法等。比如最短距离法,将类与类的距离定义为类与类之间样本的最段距离。。。
r语言中使用hclust(d, method = "complete", members=NULL) 来进行层次聚类。
其中d为距离矩阵。
method表示类的合并方法,有:
single 最短距离法
complete 最长距离法
median 中间距离法
mcquitty 相似法
average 类平均法
centroid 重心法
ward 离差平方和法
?
1
2
3
4
5
6
7
8
> x <-c(1,2,6,8,11) #试用一下
> dim(x) <-c(5,1)
> d <-dist(x)
> hc1 <-hclust(d,"single")
> plot(hc1)
> plot(hc1,hang=-1,type="tirangle") #hang小于0时,树将从底部画起。
#type = c("rectangle", "triangle"),默认树形图是方形的。另一个是三角形。
#horiz TRUE 表示竖着放,FALSE表示横着放。
?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
> z <-scan()
1: 1.0000.8460.8050.8590.4730.3980.3010.382
9: 0.8461.0000.8810.8260.3760.3260.2770.277
17: 0.8050.8811.0000.8010.3800.3190.2370.345
25: 0.8590.8260.8011.0000.4360.3290.3270.365
33: 0.4730.3760.3800.4361.0000.7620.7300.629
41: 0.3980.3260.3190.3290.7621.0000.5830.577
49: 0.3010.2770.2370.3270.7300.5831.0000.539
57: 0.3820.4150.3450.3650.6290.5770.5391.000
65:
Read 64items
> names
[1] "shengao""shoubi""shangzhi""xiazhi""tizhong"
[6] "jingwei""xiongwei""xiongkuang"
> r <-matrix(z,nrow=8,dimnames=list(names,names))
> d <-as.dist(1-r)
> hc <-hclust(d)
> plot(hc)
然后可以用rect.hclust(tree, k = NULL, which = NULL, x = NULL, h = NULL,border = 2, cluster = NULL)来确定类的个数。 tree就是求出来的对象。k为分类的个数,h为类间距离的阈值。border是画出来的颜色,用来分类的。
?
1
2
3
> plot(hc)
> rect.hclust(hc,k=2)
> rect.hclust(hc,h=0.5)
result=cutree(model,k=3) 该函数可以用来提取每个样本的所属类别
二、动态聚类k-means
层次聚类,在类形成之后就不再改变。而且数据比较大的时候更占内存。
动态聚类,先抽几个点,把周围的点聚集起来。然后算每个类的重心或平均值什么的,以算出来的结果为分类点,不断的重复。直到分类的结果收敛为止。r语言中主要使用kmeans(x, centers, iter.max = 10, nstart = 1, algorithm =c("Hartigan-Wong", "Lloyd","Forgy", "MacQueen"))来进行聚类。centers是初始类的个数或者初始类的中心。iter.max是最大迭代次数。nstart是当centers是数字的时候,随机集合的个数。algorithm是算法,默认是第一个。
?
使用knn包进行Kmean聚类分析
将数据集进行备份,将列newiris$Species置为空,将此数据集作为测试数据集
>newiris <- iris
>newiris$Species <- NULL
在数据集newiris上运行Kmean聚类分析, 将聚类结果保存在kc中。在kmean函数中,将需要生成聚类数设置为3
>(kc <- kmeans(newiris, 3))
K-means clustering with 3 clusters of sizes 38, 50, 62: K-means算法产生了3个聚类,大小分别为38,50,62.
Cluster means: 每个聚类中各个列值生成的最终平均值
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.006000 3.428000 1.462000 0.246000
2 5.901613 2.748387 4.393548 1.433871
3 6.850000 3.073684 5.742105 2.071053
Clustering vector: 每行记录所属的聚类(2代表属于第二个聚类,1代表属于第一个聚类,3代表属于第三个聚类)
[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[37] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[73] 2 2 2 2 2 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 3 2 3 3 3 3 2 3
[109] 3 3 3 3 3 2 2 3 3 3 3 2 3 2 3 2 3 3 2 2 3 3 3 3 3 2 3 3 3 3 2 3 3 3 2 3
[145] 3 3 2 3 3 2
Within cluster sum of squares by cluster: 每个聚类内部的距离平方和
[1] 15.15100 39.82097 23.87947
(between_SS / total_SS = 88.4 %) 组间的距离平方和占了整体距离平方和的的88.4%,也就是说各个聚类间的距离做到了最大
Available components: 运行kmeans函数返回的对象所包含的各个组成部分
[1] "cluster" "centers" "totss" "withinss"
[5] "tot.withinss" "betweenss" "size"
("cluster"是一个整数向量,用于表示记录所属的聚类
"centers"是一个矩阵,表示每聚类中各个变量的中心点
"totss"表示所生成聚类的总体距离平方和
"withinss"表示各个聚类组内的距离平方和
"tot.withinss"表示聚类组内的距离平方和总量
"betweenss"表示聚类组间的聚类平方和总量
"size"表示每个聚类组中成员的数量)
创建一个连续表,在三个聚类中分别统计各种花出现的次数
>table(iris$Species, kc$cluster)
1 2 3
setosa 0 50 0
versicolor 2 0 48
virginica 36 0 14
根据最后的聚类结果画出散点图,数据为结果集中的列"Sepal.Length"和"Sepal.Width",颜色为用1,2,3表示的缺省颜色
>plot(newiris[c("Sepal.Length", "Sepal.Width")], col = kc$cluster)
在图上标出每个聚类的中心点
〉points(kc$centers[,c("Sepal.Length", "Sepal.Width")], col = 1:3, pch = 8, cex=2)
三、DBSCAN
动态聚类往往聚出来的类有点圆形或者椭圆形。基于密度扫描的算法能够解决这个问题。思路就是定一个距离半径,定最少有多少个点,然后把可以到达的点都连起来,判定为同类。在r中的实现
dbscan(data, eps, MinPts, scale, method, seeds, showplot, countmode)
其中eps是距离的半径,minpts是最少多少个点。 scale是否标准化(我猜) ,method 有三个值raw,dist,hybird,分别表示,数据是原始数据避免计算距离矩阵,数据就是距离矩阵,数据是原始数据但计算部分距离矩阵。showplot画不画图,0不画,1和2都画。countmode,可以填个向量,用来显示计算进度。用鸢尾花试一试
?
1
2
3
4
5
6
7
8
9
10
11
> install.packages("fpc", dependencies=T)
> library(fpc)
> newiris <-iris[1:4]
> model <-dbscan(newiris,1.5,5,scale=T,showplot=T,method="raw")# 画出来明显不对 把距离调小了一点
> model <-dbscan(newiris,0.5,5,scale=T,showplot=T,method="raw")
> model #还是不太理想……
dbscan Pts=150MinPts=5eps=0.5
012
border 34518
seed 04053
total 344571
向量是用于存储数值型、字符型或逻辑型数据的一维数组。向量只可以包含一种数据。在R中创建和操作向量很简便,下面的例子显示了如何用函数c() 或者冒号运算符来建立向量以及如何查询、修改、截取一部分向量。
在控制台中键入下列命令建立一个元素为字符串的向量并查询首元素:
键入下列命令建立一个元素为1、2、3、4、5的向量并计算向量元素之和:
创建一个新向量,元素包括2、4、6、8、10,并对其进行相关操作
如果想要初始化一个向量然后再添加内容,可以用vector()函数,vector()函数默认创建逻辑型向量。可以用mode参数指定向量类型。如果不知道向量中元素的个数,可以将个数设置为0,然后再将数据添加到向量末尾。
创建一个长度为3的逻辑型向量,未赋值元素默认为FALSE:
创建一个长度为3的数值型向量,查看元素类型并将3.1赋值于第二个元素: