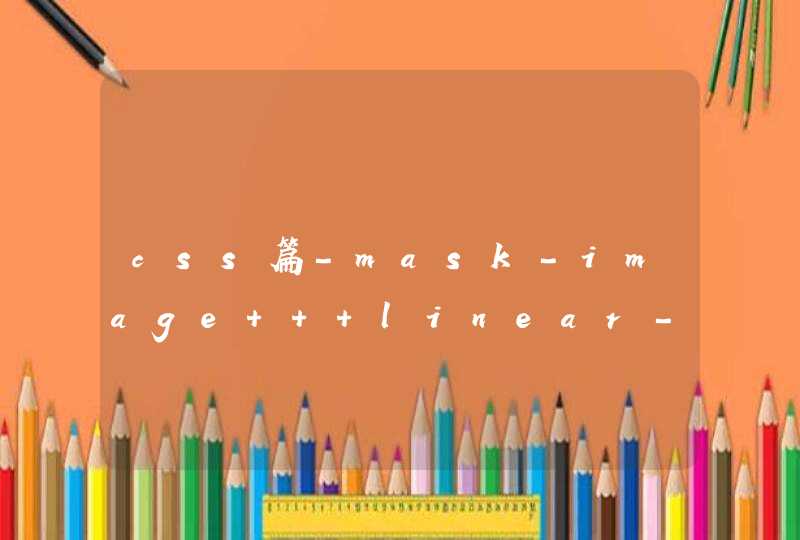提供思路如下:
首先用当年的年份减去每个人的年龄得到对应的出生年,然后把出生年份转换成字符串类型,用substr函数分别提取前两位和后两位,前两位的数值减去1是世纪,后两位去的第一位是年代。
就这么简单
导入hellodb.sql生成数据库。(1)在表中,查询女性年龄大,且为女性的同学的名字和年龄。
(2)以ClassID为分组依据,显示每组的平均年龄。
(3)显示第2题中平均年龄大于30的分组及平均年龄。
(4)显示以L开头的名字的同学的信息。
(5)显示TeacherID非空的同学的相关信息。
(6)以年龄排序后,显示年龄最大的前10位同学的信息。
您好,这样的:在R中,1等于TRUE,0等于FALSE。以上等式中,符号的优先顺序为()、!、==。因些,等式中,首先计算(7==6),结果为FALSE;然后再进行!运算,结果为TRUE。TRUE再与1进行==计算,得到整个计算结果为TRUE。
pbinom是求二项分布的分布函数值。
比如X服从B(100,0.5)那么P(X<=55)怎么求?用pbinom(55,100,0.5)
那P(X>55)呢,当然你可以用1-pbinom(55,100,0.5) 或者 pbinom(55,100,0.5,lower.tail=TRUE)
因为pbinom默认是lower.tail=FALSE 即分布函数,若lower.tail=TRUE则求生存函数。