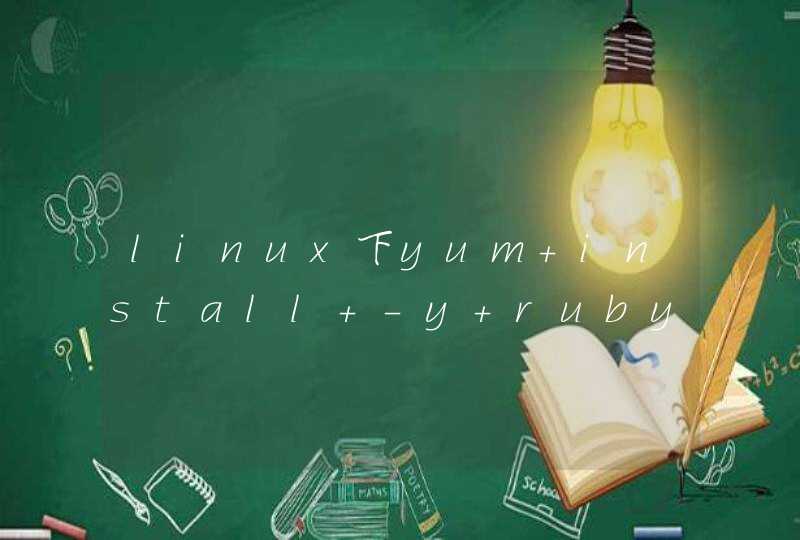filter 函数原型如下:
第一个参数是判断函数(返回结果需要是 True 或者 False),第二个为序列,该函数将对 iterable 序列依次执行 function(item) 操作,返回结果是过滤之后结果组成的序列。
简单记忆:对序列中的元素进行筛选,获取符合条件的序列。
返回结果为:,使用 list 函数可以输入序列内容。
map 函数原型如下:
该函数运行之后生成一个 list,第一个参数是函数、第二个参数是一个或多个序列;
下述代码是一个简单的测试案例:
上述代码运行完毕,得到的结果是:。使用 print(list(my_new_list)) 可以得到结果。
map 函数的第一个参数,可以有多个参数,当这种情况出现后,后面的第二个参数需要是多个序列。
map 函数解决的问题:
reduce 函数原型如下:
第一个参数是函数,第二个参数是序列,返回计算结果之后的值。该函数价值在于滚动计算应用于列表中的连续值。
测试代码如下:
最终的结果是 6,如果设置第三个参数为 4,可以运行代码查看结果,最后得到的结论是,第三个参数表示初始值,即累加操作初始的数值。
简单记忆:对序列内所有元素进行累计操作。
zip 函数原型如下:
zip 函数将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一样,则返回列表长度与最短的对象相同,利用星号( * )操作符,可以将元组解压为列表。
测试代码如下:
展示如何利用 * 操作符:
输出结果如下:
简单记忆:zip 的功能是映射多个容器的相似索引,可以方便用于来构造字典。
enumerate 函数原型如下:
参数说明:
该函数用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
测试代码如下:
返回结果为:。
本文涉及的函数可以与 lambda 表达式进行结合,能大幅度提高编码效率。最好的学习资料永远是官方手册
函数原型 :range(start, end, scan):参数含义 :start:计数从start开始。默认是从0开始。例如range(5)等价于range(0, 5)
end:技术到end结束, 但不包括end. 例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
scan:每次跳跃的间距,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
里面的一个坑:
我的理解是for循环是针对里面的每一个在range(5)的数进行循环里面的操作。
程序的输出结果如下:
函数:len()
1:作用: 返回字符串、列表、字典、元组等长度
2:语法: len(str)
3:参数:
str:要计算的字符串、列表、字典、元组等
4:返回值 :字符串、列表、字典、元组等元素的长度
5:实例
用len()求得数组a的长度为4,其中range(len(a))等价于range(4),输出结果都为[0,1,2,3]
choice()需要import random
功能:返回列表、元组、字符串的随即项
这是函数注解,Python 3.x引入,它的特点有
对函数的参数进行类型注解,以冒号标记
对函数的返回值进行类型注解,以箭头标记
只对函数参数或返回值做一个辅助的说明,并不对函数参数或返回值进行类型检查
提供给第三方工具,做代码分析,发现隐藏bug
函数注解的信息,保存在__annotations__属性中
注解本身是一个字典类型的数据
你的程序我帮你完善了(函数注解部分的解释见注释),你看看吧
from typing import Listdef f(a) -> List[dict]: #函数注解,返回一个字典列表,但是它不对返回值类型进行检查
print(a) #打印字典
return [a] #返回字典列表
print(f.__annotations__) #打印函数注解
l={'Name': 'Zara','Age':17} #把字典传入函数
print(f(l)) #打印函数返回值
源代码(注意源代码的缩进)