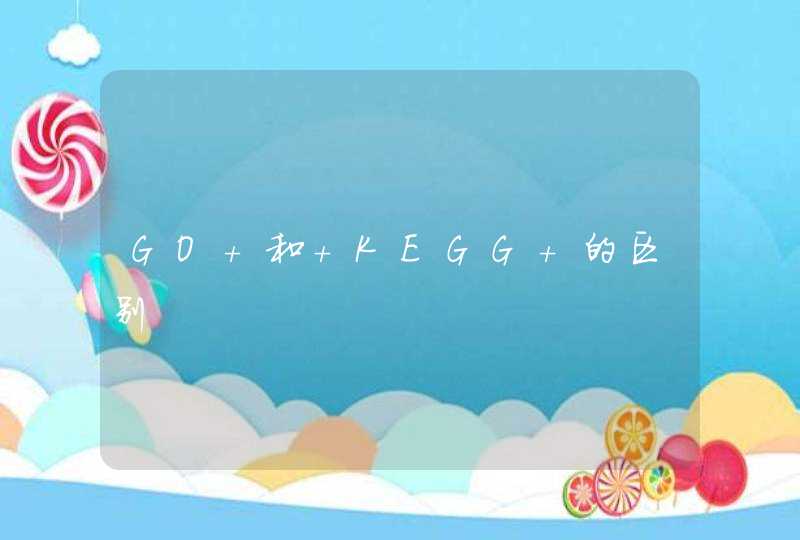:定量不同环境因子对群落变化的解释比例,第1张")
衷心的感谢每一位知识的奉献者。。。。
VPA ,全称Variance Partitioning Analysis,中文成为方差分解分析,该分析的目的是 确定指定的环境因子对群落结构变化的解释比例 。
我们使用CCA/RDA的排序分析方法可以得到所有参与分析的环境因子对群落变化的解释比例。
那么在进行VPA时,首先就要对这些环境因子进行一个分类,然后在约束其它类环境因子的情况下,对某一类环境因子进行排序分析,这种分析也成为偏分析,即partial CCA/RDA。
在对每一类环境因子均进行偏分析之后,即可计算出每一个环境因子单独以及不同环境因子相互作用分别对生物群落变化的贡献。
分析实战
这里使用 R语言vegan包的varpart()函数 进行VPA分析,之后使用plot函数对结果进行可视化。
VPA是确定不同类型环境因子对群落变化的解释,那么首先就要对环境因子进行一个分类, 这个类怎么分呢 ?
简单的说就是 你自己想怎么分就怎么分 ,根据你研究的实际情况自己确定怎么分类。
两种环境因子分类
当分析的环境因子只有两类时,可以将两类环境因子放在不同的数据框中进行分析。
首先我们导入示例数据。
data(mite)
data(mite.env)
data(mite.pcnm)
这里mite为群落丰度数据表格,行为样本,列为物种;mite.env和mite.pcnm分别为两个环境因子的数据表格,同样行为样本,列为环境因子。
mod <- varpart(mite, mite.env, mite.pcnm, transfo="hel")
mod
进行VPA的时候, 第一个数据框为群落数据,之后两个数据框分别代表两类环境因子 ,transfo时对数据进行转换,hel为hellinger转换,可以避免分析的“弓形效应”。
在结果中我们看Individual fractions部分即可。
a为X1也就是命令中第二个数据框单独对群落变化的贡献。
c为X2也就是命令中第三个数据框单独对群落变化的贡献。
b为X1和X2的相互作用对群落变化的贡献。
d为X1和X2无法解释的群落变化。
使用plot()函数对结果进行可视化。
plot(mod, bg = c("hotpink","skyblue"))
三种及以上的分类
对与将环境因子分为3类或4类的情况,可以将环境因子放在同一个数据框中,之后使用formula的形式指定不同的分类因子。
mod <- varpart(mite, ~ SubsDens + WatrCont, ~ Substrate + Shrub + Topo,
mite.pcnm, data=mite.env, transfo="hel")
可以看到3种分类的结果就相对复杂一些,a-h的含义需要根据Partition table中的对应情况确定一下,这个我就不从头捋一遍了,感兴趣的朋友可以自行画个交集和并集的图分解一下。
为什么不捋一遍结果呢,是因为可视化之后解释的比例就直接给出了????
plot(mod, bg=2:4)
VPA最多能将环境因子分为4组,再多就不行了,不过我想也几乎不会遇到能够将环境因子分为很多组的情况。
下面是干货
做VPA分析对样本的数量有一定的要求,记得最开始使用Canoco分析的时候,如果样本数小于环境因子数目减2,软件就会报错。
也就是说 样本数目至少要比因子数目多2个 ,不要问我为什么,我也不知道为什么,没研究过具体的算法,我只是只要如果环境因子比样本数还多的话,就算做完了,结果也很奇葩,根本没法解释。
这对于一些大样本量的研究项目当然不成问题,但是对于一些经费有效的研究,可能样本数目就会是使用VPA的一个限制因素。
这里我有一个变通的方法,就是先 对不同分类环境因子做降维分析 ,比如说PCoA,之后使用主要的PC的结果替代环境因子, 从而达到降低实际使用因子数目的目的 。
但是 具体使用前几个PC就要不断的尝试 ,根据结果进行调整了。
对于结果的可视化,R默认的结果图确实不是很好看,关键还不太好调整,大家可以先默认出一个图,然后把每一部分的解释比例记下来,之后使用在线的Venn图绘制工具,画一个自己满意的只有圆圈的Venn图,再手动把解释比例和环境因子的名称给P上去
文章发表于nature review genetics: Integrative single- cell analysis ,作者是Tim Stuart与 Rahul Satija 。做过单细胞分析的对他们应该不陌生。
scRNA-seq技术的发展契合了研究个体细胞表观遗传、空间研究、蛋白质组与谱系信息的方法需要,这为研究多类型数据的综合方法提出了独特的机遇与挑战。综合分析可以发现细胞之间的模式关系,获取细胞的整体状态信息,产生涵盖不同样本与不同研究手段的数据集。该文重点讨论了单细胞基因表达数据与其他类型的单细胞分析方法的整合。
多模态(Multimodal)数据 :多种类型数据的组合,如RNA与蛋白质数据组合,是一种多维度数据,类似多组学。
单模态 :单个类型数据
Pseudotime :拟时分析
联合聚类(Joint-clustering) :通过联合不同类型数据对细胞进行分组。
典型相关分析(CCA) : 利用综合变量对之间的相关关系来反映两组指标之间的整体相关性的多元统计分析方法。
动态时间规整(Dynamic time warping) :一种局部拉伸或压缩两个一维矢量以校正一个矢量相对于另一个矢量的滞后的方法。
MNNs :标准化基因表达空间中最临近的细胞。聚类用校正批次效应。
梯度推进(Gradient boosting) :一种预测模型算法。
随着分子生物学、微流控与纳米技术的发展,催生了许多类型的单细胞测序技术。过去的方法集中在单模态测量上,如DNA序列、RNA表达量和 染色质可及性 上。虽然这些技术促进了我们对细胞多样性与发育景观的理解,但是它们并不能很好地解析单细胞内分子间互作关系。而这些互作关系是深入探索细胞状态的关键。此外,随着可用数据集规模的快速增长,迫切需要用于标准化与联合分析且考量到批次效应与个体差异的计算方法。
scRNA-seq是应用最为广泛的单细胞测序技术之一。而后出现了一系列互补技术如单细胞基因组、表观基因组和蛋白质组分析技术,涵盖了单细胞基因组测序( Vitak, S. A. et al., 2017 Navin, N. et al., 2011 )、染色质可及性( Pott, S., 2017 Corces, M. R. et al., 2016 Buenrostro, J. D. et al., 2015 Cusanovich, D. A. et al., 2015 Lake, B. B. et al., 2018 )、DNA甲基化( Luo, C. et al., 2017 Smallwood, S. A. et al., 2014 Guo, H. et al., 2013 Mulqueen, R. M. et al., 2018 )、膜蛋白( Stoeckius, M. et al., 2017 Peterson, V. M. et al., 2017 )、小RNA( Faridani, O. R. et al., 2016 )、组蛋白修饰( Gomez, D. te al., 2013 Rotem, A. et al., 2015 )和染色体构象( Ramani, V. et al., 2017 Nagano, T. et al., 2013 )等技术。目前已开发出研究单细胞空间结构和谱系信息的方法( Frieda, K. L. et al., 2017 Shah, S. et al., 2016 )。
单细胞多模态综合分析方法示意
单模态与多模态分析方法汇总
CEL-seq :线性扩增测序法
CITE- seq :膜蛋白丰度与基因表达水平测定
G&T-seq :基因组转录组测序
LINNAEUS :谱系追踪
MARS-seq :大规模平行单细胞RNA测序
MEMOIR :谱系与空间结构测定
MERFISH :主要是细胞间结构测定
osmFISH :环状单分子荧光原位杂交,空间结构测定
REAP- seq :膜蛋白丰度与基因表达水平测定
scATAC-seq :单细胞空间结构测定
scBS-seq :单细胞甲基化测序
scChIP-seq :单细胞ChIP-seq
scGESTALT :结合CRISPR-cas9的谱系追踪弄方法
scHi-C-seq :测定染色体组装
sciATAC-seq :结合index转座酶的scATAC-seq
sci-CAR :利用index联合分析mRNA和染色质可及性谱
sci-MET :利用index分析单细胞甲基化水平
sci-RNA-seq :结合index的scRNA-seq
SCI-seq :单细胞组合标记测序,检测CNV
scM&T-seq :单细胞甲基化组和转录组测序,可研究未知的DNA甲基化与基因表达之间的关系
scNOMe- seq :核小体占位与甲基化组测序
scRRBS :单细胞限制性代表区域甲基化测序
scTHS- seq :单细胞转座体超敏性位点测序
seqFISH :内含子序贯荧光原位杂交,扩展观测到基因数量
snmC-seq :单核甲基胞嘧啶测序
SNS :单核测序
SPLiT-seq :丐版scRNA-seq
STARmap :原位单细胞测序
理想的实验流程应当全面洞悉细胞的所有方面,包括分子状态、空间构象、胞外环境互作的全部过程。尽管当下技术手段无法做到,但多模态技术与综合计算方法可以是我们离该目标越来越近。文章希望提出整合单细胞转录组学、基因组学、表观组学与蛋白组学的数据统一分析方法,重点在结合其他数据类型分析scRNA-seq数据,尤其是整合来自于同一细胞的不同类型数据。
文章分为四大块,首先探讨了多模态单细胞分析方法,其次研究了不同实验不同数据整合分析,然后讨论了单细胞空间测序数据整合分析方法,最后给出了整合分析方法的前景与必要性。
最初的单细胞分析方法主要关注细胞某状态下的某类分子水平。而现在更引人瞩目的是同时分析单细胞内多种分子以建立更全面的单细胞分子视图。通常这些方法是将scRNA-seq数据与其它分析手段的结合,目前主要有四种策略从单细胞中得到多模态数据:
严格来说这种方法算单模态。
一些scRNA-seq workflow采用流式分选细胞,随后进行scRNA-seq(MARS-seq/Smart-seq/2),这样可以同时获得单细胞与对应的荧光信号,将荧光所表示的蛋白质水平与转录组在同一细胞中关联( Ramsköld, D. et al., 2012 Jaitin, D. A. et al., 2014 Picelli, S. et al., 2013 )。早期研究( Hayashi, T. et al., 2010 )利用FACS结合半定量RT-PCR(作者称之为FBSC‐PCR),结合scRNA-seq,明确了细胞表面marker可以区分细胞类型与状态( Wilson, N. K. et al., 2015 该文结合了Smart-seq2),( Paul, F. et al., 2015 该文结合了MARS-seq)和鉴定稀有细胞的思路。 Paul, F. et al., 2015 与 Nestorowa, S. et al., 2016 利用该workflow研究发现了小鼠造血祖细胞由转录组定义不同细胞簇的免疫表型, Wilson, N. K. et al., 2015 则分离了小鼠HSCs,鉴定细胞维持干性相关的表面marker。但是囿于荧光光谱的重叠现象,利用该法测到的每个细胞的参数范围有限。
针对荧光无法分选的部分,FACS显然是不合适的,尤其是需要同时测得单细胞基因组与胞内蛋白的scRNA-seq实验。此时需要物理分离或通过不同tag筛选出不同组分。
G&T-seq通过加入oligo(dT)特异性分离mRNA同时保留基因组DNA从而实现了基因组转录组平行测序( Macaulay, I. C. et al., 2015 )DR-seq通过则通过加入barcode特异扩增cDNA序列实现基因组转录组平行测序( Dey, S. S. et al., 2015 )。这使得单细胞基因表达水平与其对应基因型联系起来,深度揭示单细胞间DNA拷贝数变异与染色体重排对下游mRNA丰度的具体关联。这些方法适用于研究体细胞基因高度变异的肿瘤组织。
DNA甲基化与转录组水平结合研究是基于 Macaulay, I. C. et al., 2015 的G&T-seq和 Smallwood, S. A. et al., 2014 的scBS- seq技术发展的,同普通BSP一样,用亚硫酸氢钠处理DNA片段随后进行扩增,结合G&T-seq,可以分析同一细胞内的DNA甲基化模式和基因表达数据( Angermueller, C. et al., 2016 )。由于DNA甲基化存在不稳定性和异质性,因此若要研究DNA甲基化与基因表达间的关系,则必须将表观基因组变异与细胞间的异质性区别开来。
通过DNA甲基化与转录组关联分析,为启动子甲基化与基因表达间的负相关性提供深层次的证据。此外,利用barcode系统选择性标记基因组DNA与cDNA,结合index系统,可以对数千个单细胞进行染色质可及性与基因表达水平间的关联分析,同时鉴定出影响基因表达的顺式调控元件( Cao, J. et al., 2018 )。
关于胞内蛋白与mRNA关联研究,有两种思路可供借鉴。其一( Darmanis, S. et al., 2016 )是将FACS sort到的细胞裂解后分离裂解液,分别进行蛋白质与RNA定量。作者采用 PEA (邻近探针延伸分析) 检测蛋白并用RT-qPCR定量,采用qRT-PCR定量mRNA。该法可以同时检测82个mRNA/75个蛋白;其二( Genshaft, A. S. et al. )是将FACS sort到的细胞在微流控芯片中同时进行逆转录和PEA而不分离裂解液。该法可以同时检测96个mRNA/38个蛋白。这两种方法检测的蛋白与mRNA数量与质量均有限。
这些技术的出现表明若将可以细胞信息转化为有序的barcode,我们就可以在分析单细胞转录组时将这些信息同时获取。这种策略不仅适用于分析细胞的自然状态,也适用于大规模基因扰动研究。目前有Perturb-Seq( Dixit, A. et al., 2016 )和CRISPR-Seq( Adamson, B. et al., 2016 Datlinger, P. et al., 2017 Jaitin, D. A. et al., 2016 ),他们将scRNA-seq与CRISPR-cas9结合进行遗传筛选,使得研究正向遗传学的大规模基因扰动试验成为可能。具体原理是给单个基因扰动和受到影响的细胞添加barcode,通过scRNA-seq能够鉴定出这两者,从而推断CRISPR靶向基因和由此产生的单个细胞的转录谱间的关系。目前应用在基因调控网络( Dixit, A. et al., 2016 )、未折叠蛋白反应( Adamson, B. et al., 2016 )、免疫细胞分化发育( Datlinger, P. et al., 2017 )和T细胞受体激活( Jaitin, D. A. et al., 2016 ),非编码区调控元件( Klann, T. S. et al., 2017 )。此外,还可以结合CRISPR-dcas9系统,扩展到转录调控、表观遗传调控领域中( Thakore, P. I. et al., 2016 Liu, X. S. et al., 2016 Hilton, I. B. et al., 2015 Konermann, S. et al., 2015 Gilbert, L. A. et al., 2017 ),18年发展了同时靶向和敲除基因的技术( Boettcher, M. et al., 2018 )。
另一个应用是结合CRISPR-cas9的谱系追踪技术。单细胞谱系追踪是去年的大热方向之一,此处提到三种mRNA+lineage方法: scGESTALT 、 ScarTrace 、 LINNAEUS 。这三种方法各有不同,但大体是利用CRISPR-cas9连续切割结合到基因组上的barcode,细胞会用NHEJ来应对这种损伤。但NHEJ容易出错,从而在DNA序列中产生随机突变,这些突变通过细胞分裂进行遗传,结合scRNAseq利用这些突变作为复合barcode来构建组织或器官发育谱系。
另一种略有不同的方法是 MEMOIR ,它结合smFISH与CRISPR-cas9系统,可以同时检测细胞谱系与空间位置。
普通的scRNA-seq流程除了可以做转录本丰度外,还可以进行诸如体细胞突变、遗传变异、RNA isoform等分析。
关于体细胞突变目前已有研究( Lodato, M. A. et al., 2015 ),该文通过对人大脑的少量单细胞全基因组测序,分析了发生的细胞突变,构建了人大脑神经细胞谱系。作者发现突变大多发生在高转录活性相关位置,这表明可能可以通过scRNA-seq数据来分析神经细胞突变情况,根据转录状态重构神经细胞谱系。此外,分析scRNA-seq数据中的拷贝数变异,可以研究癌症非整倍体与异质性等情况( Tirosh, I. et al., 2016 Fan, J. et al., 2018 )。
单细胞分析也为理解DNA自然变异如何影响基因表达与细胞状态提供了新思路。有研究结合GWAS+scRNAseq,鉴定出了不同个体之间的eQTL( Kang, H. M. et al., 2018 )。
多模态测序策略正在催生与之相匹配的数据分析方法。多模数据集可以检测到细胞间的细微差异,而单模数据很可能无法做到这一点。由于scRNAseq数据存在dropout,故而它更容易忽略细胞间的细微差别;但与来自同一细胞的其他数据互补分析可以改善这一问题。例如,很难通过scRNA-seq数据区分不同的T细胞亚群,但联合膜蛋白分析则可以显著提高亚群分辨率( Stoeckius, M. et al., 2017 ),同样,RNA+chromatin、RNA+methylation联合可能揭示单个细胞间的调控异质性,不再赘述。
单细胞多模态分析思路很可能受到bulk-seq多组学联合分析的启发( Meng, C. et al., 2016 ), Argelaguet 开发了一种名为MOFA( multi- omics factor analysis)的方法,该方法在多组学bulk-seq数据中效果良好,同时测试了单细胞DNA甲基化数据与RNA数据联合处理情况,效果也可以。这暗示适用于bulk-seq的多组学数据处理方式可能也适用于单细胞多模态数据。鉴于单细胞数据规模远超bulk-seq,多视图机器学习不失为一种重要的补充手段( Colomé- Tatché, M. &Theis, F. J., 2018 )。
单细胞多模态研究策略为解析细胞内不同组分间的关系提供了新方法。如CITE-seq和REAP-seq可以轻易鉴别出相关度较低的RNA-protein模块,表明此处存在活跃的转录后调节。还有一个很有意思的是通过测量剪接过的成熟RNA与未剪接RNA的相对丰度,可以建立RNA与蛋白的关联动态模型( La Manno, G. et al., 2018 )。
此外,还可以在不同类型数据间建立统计模型。前面提到的sci-CAR文章建立了染色质可及性与基因表达水平间的统计模型,通过染色质可及性数据估计细胞内基因表达水平( Cao, J. et al., 2018 ),另一组研究人员建立了gRNA与基因表达水平间的线性回归模型,用以识别细胞应答的前后关系,重构转录网络(Perturb-Seq( Dixit, A. et al., 2016 ))。通过这种手段可以研究目标物种复杂的调控网络。
前面主要讲了在同一测序实验同一批细胞进行的多模态数据整合,而不同测序实验数据整合分析才是亟需解决的关键问题。同bulk seq 数据一样,处理批次效应是综合分析不同实验室、不同workflow产出数据的首要问题(SVA包( Leek, J. T. 2014 ))。然而目前bulk seq水平的处理方法无法处理单细胞数据(( Haghverdi, L, et al., 2018 ,作者用MNN处理数据,该法在 mnnpy 中得到改进) Butler, A, et al,. 2018 )。目前最新方法利用 CCA / MNN 可以识别出两个数据集间共有的部分,判定细胞间共有的生物学状态,然后以这些相同状态的细胞为基准消除批次效应。
此处作者介绍了他自己在Seurat V2中开发的方法( Satija, R, et al., 2015 ),该法用 CCA 鉴别出不同数据集间相同的细胞类型且可以避免出现由批次效应或常规PCA造成的假阳性细胞类型;接下来采用动态时间规整算法校正数据集间细胞密度差异。这两步骤可以将细胞投影到一个低维空间,具有相同生物学状态的细胞相互接近且消除了不同数据集带来的影响。
另一种方法即mnnCorrect,最早用于计算机领域图形识别。该法寻找不同数据集间最接近的细胞,将之判定为潜在的状态相同细胞,随后利用成对MNNs距离计算一个批次参数(batch vector),用以校正原始表达矩阵( Haghverdi, L., 2018 )。
CCA/mnnCorrect在整合处理不同来源的scRNA-seq数据时表现良好。这将极大提升发现稀有细胞、微弱转录差异细胞及与之对应maker的能力( Haghverdi, L, et al,.2018 ; Butler, A,et al,. 2018 ) 。这为建立一个统一的单细胞参考数据集提供了依据。在此基础上,scRNA-seq数据整合分析得到了快速发展( Hie, B. L, et al., 2018 Barkas, N. et al., 2018 Park, J.-E., 2018 Korsunsky, I. et al., 2018 Stuart, T. et al., 2018 Welch, J. et al., 2018 )。这种多数据集整合分析的应用远不止用于校正批次效应这么单一。它可以在单细胞尺度上深入比较细胞间的状态,发现细胞对环境及基因扰动的特异性响应,对不同疾病及不同治疗下的患者的测序数据进行标准化。
scRNA-seq数据整合分析还可以扩展至跨物种分析。 Karaiskos,N 比较了两种果蝇早期胚胎的空间基因表达模式,通过构建空间基因表达图谱,该研究系统比较了两个果蝇的同源基因表达谱,鉴定出了彼此间的进化波动。 Tosches 比较了爬行动物与哺乳动物脑细胞间的相关性。 Baron 分析了人与小鼠胰岛细胞scRNA-seq数据,鉴定出了二者间的保守亚群。 Alpert 开发出了cellAlign,在一维水平上比对了人与小鼠的拟时轨迹,发现人胚胎合子激活要比小鼠晚,小鼠中比人活跃的基因皆与蛋白合成相关。跨物种分析未来是光明的,但对于多物种整合分析而言,精确鉴定物种间同源基因是多物种整合分析至关重要的一步。
以细胞分类信息的形式串联不同的scRNA-seq数据集,或者借鉴到自己实验中,是优于合并数据集然后de novo聚类这种方法的。且随着 有参细胞图谱 的开发,这种方式将更加寻常。目前已开发对应方法: scmap- cell &scmap- cluster ,其中scmap-cell 用乘积量化( product quantization )算法进行比对,而scmap-cluster则用于识别未知数据集中的cluster。
利用已有的注释数据集,目前开发的新方法采用 奇异值分解 、 线性判别分析 和 支持向量机 算法来对细胞进行分类。此外,随着引用数据集的大小、范围与深度越来越高,监督聚类在解析细胞类型方面要比无监督聚类强得多。通过以上这些方法,可以更精确地识别并解析细胞亚群。
satija已有相关文章研究: Comprehensive Integration of Single-Cell Data
这一部分讲的是将scRNA-seq数据与其它不同来源和类型数据诸如甲基化、染色质结构等整合分析的方法。
将scRNA-seq数据与其它类型、不同来源的单细胞数据整合分析是无法提取到数据间的共同特征的,因为它们不是一个类型的数据,需要不同的分析方法。这点在基于基因组的数据(如染色质可及性与甲基化数据)与基于基因的数据(如基因与蛋白表达数据)间整合分析尤为明显。但如果这些数据来自于同一类细胞群,由于存在着共同的生物学状态,此时可以联立分析以发现不同数据集类型间的对应关系。
MATCHER 是一种在一维水平上比较不同类型测序数据拟时轨迹的方法。简单来说就是比对不同类型测序数据的拟时轨迹,以确定这些数据集间的对应关系。这种方法可以识别不同数据集间的“等效细胞”而不需预先知道彼此间的对应关系。开发者用scM&T- seq( Angermueller, C. et al., 2016 )和scRNA-seq数据做了验证,准确预测了DNA甲基化与基因表达之间的关系。
其他sc-seq数据不同于scRNA-seq数据一样可以借助Marker解析细胞类型,因此可以利用scRNA-seq解析出的细胞信息为其他sc-seq数据分析做参考。有研究( Lake, B. B. et al., 2018 )对不同脑组织切片进行了单核RNAseq(snRNA-seq)与单细胞转座子超敏性位点测序(scTHS-seq),通过梯度推进算法利用单细胞基因表达谱指导了染色质可及性测序数据集的细胞分类:作者首先鉴别出snRNA-seq数据集与scTHS-seq数据集共有的细胞亚群,训练一个可以将基因表达与染色质可及性数据关联的模型;然后利用该模型去分类scTHS-seq中剩余未被分类的细胞。这种方法可以更细致地对大脑组织中的细胞进行分类。同样,可以整合scATAC-seq数据集来分析单细胞DNA甲基化或转座酶染色质可及性间的细胞分类。
目前正在开发的新方法有利用假定等价特征、或识别在所有类型数据中的假定相关共享特征来进行数据交叉模态分类。 Welch 开发了一种集成非负矩阵分解(iNMF)的方法,名为LIGER,可以跨模态整合数据。他们对同一类型 皮质细胞 分别进行了亚硫酸盐测序(snmC- seq)与scRNA-seq并对其进行了分类。他们假设基因体甲基化与其表达水平负相关从而整合了不同模态测序数据进行细胞分类。在seurat v3.0中,作者也引入了假定等价特征或关联特征进行多模态整合数据细胞分类的方法。这些方法优点如上所述,即可以利用scRNA-seq的细胞分类信息来指导scATAC-seq数据细胞分类,鉴别出染色质可及性与DNA甲基化的细胞特异模块。
组织中细胞的空间结构常反映出细胞间的功能差异与细胞命运和谱系的差异。不同基因表达引导细胞向不同方向分化,不同细胞精确排列形成不同组织。关键是单细胞实验通常在分析前细胞已被解离,组织原位信息无法保留,scRNA-seq得到的表达谱不能完全反应细胞空间信息。具有相似基因表达谱的细胞可能存在于不同的空间位置中,故而细胞分离过程中空间信息的缺失是很多单细胞实验的主要缺点。结合高分辨率基因表达谱与空间表达图谱 (spatial expression maps) 将细胞空间坐标与基因表达谱联系起来,可以解决这一问题。有两类方法:计算模型或者RNA原位定量,可以同时收集到细胞空间坐标与基因表达值。
通过基因云获取文件的项目:在下载链接中,下载“各分类学水平分类单元丰度表”。
派森诺基因云在对微生物群落进行研究时,除了分析不同群落样本之间在微生物群落组成、功能上的差异外,往往还想了解,具体有哪些因素会影响微生物群落,使其组成和功能发生变化?其中,哪种因素又占据了主导作用?
为了回答这一问题,需要将微生物群落样本的相关数据,与其对应的环境因子数据进行关联分析。在众多关联分析的方法中,出镜率最高的,就是ASV分析啦。
ASV分析一般需要使用CANOCO软件或运用R语言进行分析,这对生信小白来说,挑战还是很大滴。现在,RDA/CCA分析已经在派森诺基因云的“云图汇”模块中发布上线啦。