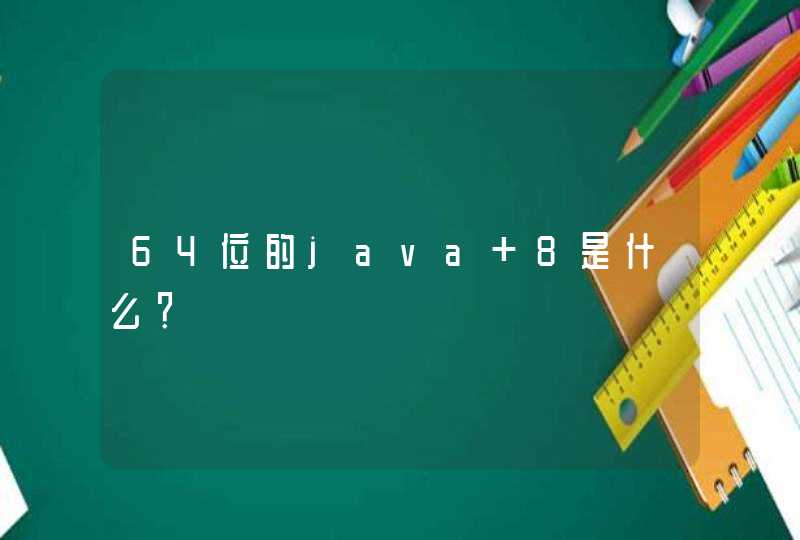拼接字符串,无外乎四种方式,采用“+”,“fmt.Sprintf()”,"bytes.Buffer","strings.Builder"
上面我们创建10万字符串拼接的测试,可以发现"bytes.Buffer","strings.Builder"的性能最好,约是“+”的1000倍级别。
这是由于string是不可修改的,所以在使用“+”进行拼接字符串,每次都会产生申请空间,拼接,复制等操作,数据量大的情况下非常消耗资源和性能。而采用Buffer等方式,都是预先计算拼接字符串数组的总长度(如果可以知道长度),申请空间,底层是slice数组,可以以append的形式向后进行追加。最后在转换为字符串。这申请了不断申请空间的操作,也减少了空间的使用和拷贝的次数,自然性能也高不少。
bytes.buffer是一个缓冲byte类型的缓冲器存放着都是byte
是一个变长的 buffer,具有 Read 和Write 方法。 Buffer 的 零值 是一个 空的 buffer,但是可以使用,底层就是一个 []byte, 字节切片。
向Buffer中写数据,可以看出Buffer中有个Grow函数用于对切片进行扩容。
从Buffer中读取数据
strings.Builder的方法和bytes.Buffer的方法的命名几乎一致。
但实现并不一致,Builder的Write方法直接将字符拼接slice数组后。
其没有提供read方法,但提供了strings.Reader方式
Reader 结构:
Buffer:
Builder:
可以看出Buffer和Builder底层都是采用[]byte数组进行装载数据。
先来说说Buffer:
创建好Buffer是一个empty的,off 用于指向读写的尾部。
在写的时候,先判断当前写入字符串长度是否大于Buffer的容量,如果大于就调用grow进行扩容,扩容申请的长度为当前写入字符串的长度。如果当前写入字符串长度小于最小字节长度64,直接创建64长度的[]byte数组。如果申请的长度小于二分之一总容量减去当前字符总长度,说明存在很大一部分被使用但已读,可以将未读的数据滑动到数组头。如果容量不足,扩展2*c + n 。
其String()方法就是将字节数组强转为string
Builder是如何实现的。
Builder采用append的方式向字节数组后添加字符串。
从上面可以看出,[]byte的内存大小也是以倍数进行申请的,初始大小为 0,第一次为大于当前申请的最大 2 的指数,不够进行翻倍.
可以看出如果旧容量小于1024进行翻倍,否则扩展四分之一。(2048 byte 后,申请策略的调整)。
其次String()方法与Buffer的string方法也有明显区别。Buffer的string是一种强转,我们知道在强转的时候是需要进行申请空间,并拷贝的。而Builder只是指针的转换。
这里我们解析一下 *(*string)(unsafe.Pointer(&b.buf)) 这个语句的意思。
先来了解下unsafe.Pointer 的用法。
也就是说,unsafe.Pointer 可以转换为任意类型,那么意味着,通过unsafe.Pointer媒介,程序绕过类型系统,进行地址转换而不是拷贝。
即*A =>Pointer =>*B
就像上面例子一样,将字节数组转为unsafe.Pointer类型,再转为string类型,s和b中内容一样,修改b,s也变了,说明b和s是同一个地址。但是对s重新赋值后,意味着s的地址指向了“WORLD”,它们所使用的内存空间不同了,所以s改变后,b并不会改变。
所以他们的区别就在于 bytes.Buffer 是重新申请了一块空间,存放生成的string变量, 而strings.Builder直接将底层的[]byte转换成了string类型返回了回来,去掉了申请空间的操作。
Buffer 介绍
Buffer 是 bytes 包中的一个 type Buffer struct{…}
A buffer is a variable-sized buffer of bytes with Read and Write methods. The zero value for Buffer is an empty buffer ready to use.
(是一个变长的 buffer,具有 Read 和Write 方法。 Buffer 的 零值 是一个 空的 buffer,但是可以使用)
Buffer 就像一个集装箱容器,可以存东西,取东西(存取数据)
创建缓冲器
输出
写入到缓冲器
buffer在new的时候是空的,也是可以直接Write的
Write
结果
WriteString
结果
WriteByte
WriteRune
结果
从缓冲器中写出
读出缓冲器
Read
ReadByte
返回缓冲器头部的第一个byte
ReadRun
ReadRune方法,返回缓冲器头部的第一个rune
为什么n==3,而n1==1呢?我们看下ReadRune 的源码
ReadBytes
ReadBytes方法,需要一个byte作为分隔符,读的时候从缓冲器里找出第一个出现的分隔符,缓冲器头部开始到分隔符之间的byte返回。
相当于有一个分隔符
ReadString
和readBytes方法类似
读入缓冲器
ReadFrom方法,从一个实现io.Reader接口的r,把r的内容读到缓冲器里,n返回读的数量
从缓冲器取出
Next方法,返回前n个byte(slice),原缓冲器变
缓冲区原理介绍
go字节缓冲区底层以字节切片做存储,切片存在长度len与容量cap, 缓冲区写从长度len的位置开始写,当len>cap时,会自动扩容。缓冲区读会从内置标记off位置开始读(off始终记录读的起始位置),当off==len时,表明缓冲区已全部读完
并重置缓冲区(len=off=0),此外当将要内容长度+已写的长度(即len) <= cap/2时,缓冲区前移覆盖掉已读的内容(off=0,len-=off),从避免缓冲区不断扩容