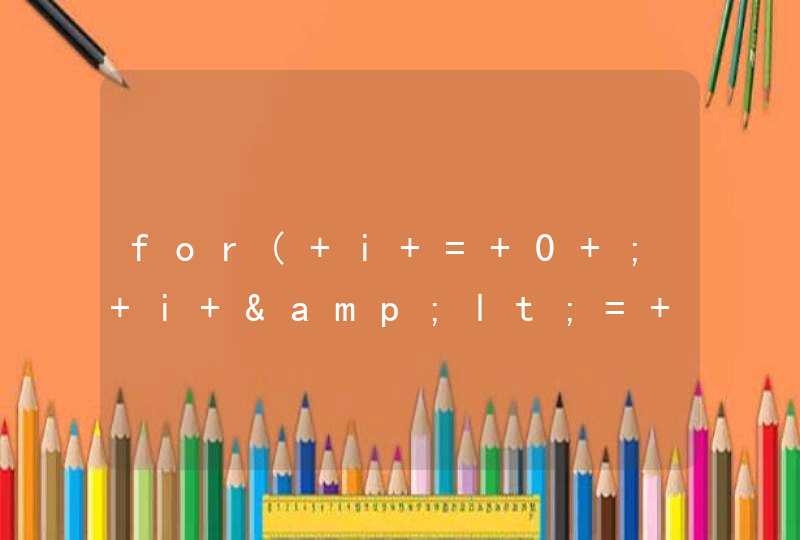1、有些页面元素被隐藏起来了->换selector解决
2、有些数据保存在js/json对象中->截取对应的串,分析解决
3、通过api接口调用->伪造请求获得数据
还有一个终极方法
4、使用phantomjs或者casperjs这种headless浏览器
Java 代码如下:<%
//得到要转换的数组---当然这里也可以是其他类型的数组
List jsList = (List) request.getAttribute("gczbh")
%>
JS 代码如下:
<script type="text/JavaScript">
function initPages()
{
var codes = new Array()
// 将JAVA中的数组转换成JS 的数组
<%
if(jsList!=null)
{
for(int i=0i<jsList.size()i++)
{
%>
codes[<%=i%>]='<%=jsList.get(i)%>'
<% }
}
%>
</script>
JavaScript有两种地方存在,一是在页面就写出来的,二是引用的。1.直接写出来的,一看就明白(右键->查看页面源代码)
2.引用的,就比如说这个页面吧,其中有下面代码:
<head>
<link href="/ikqb.css" rel="stylesheet" type="text/css">
<script type="text/javascript"src="/userlogin.js?213">
</script>
</head>
通过这段代码(src="/userlogin.js?213")知道他引用的位置是http://zhidao.baidu.com/userlogin.js,输入这个网址看看效果,就是document.domain="baidu.com"document.write("等等,这就是他引用的JS了。