









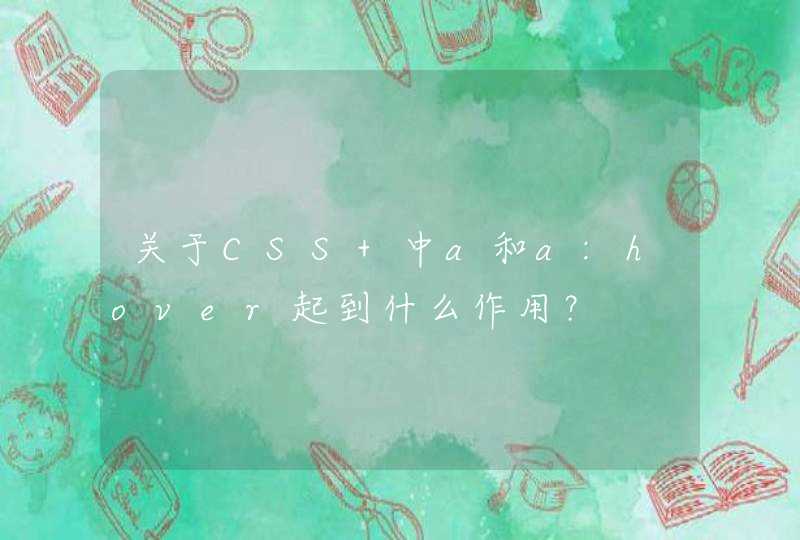






























<html>
<meta charset="UTF-8" />
<head>
<title></title>
</head>
<script src="http://libs.baidu.com/jquery/2.0.0/jquery.min.js"></script>
<style type="text/css">
</style>
<body>
<label class="goal">label的text默认内容</label>
<input type="text" name="" id="mytext" value="" placeholder="输入内容,改变左边文字" />
<button id="confirm">点击赋值以及获取</button>
</body>
<script type="text/javascript">
$(function() {
$('#confirm').click(function() {
var newstr = $('#mytext').val()
$('.goal').text(newstr)
alert('你获取了label的text:' + $('.goal').text())
})
})
</script>
</html>
Jsoup从Html文件中提取正文内容示例代码:
File input = new File("/tmp/input.html")
Document doc = Jsoup.parse(input, "UTF-8", "/example.com/")
Element content = doc.getElementById("content")
Elements links = content.getElementsByTag("a")
for (Element link : links) {
String linkHref = link.attr("href")
String linkText = link.text()
}
jsoup是一款Java的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于JQuery的操作方法来取出和操作数据。
jsoup的主要功能如下:
1. 从一个URL,文件或字符串中解析HTML;
2.使用DOM或CSS选择器来查找、取出数据;
3. 可操作HTML元素、属性、文本;





























