







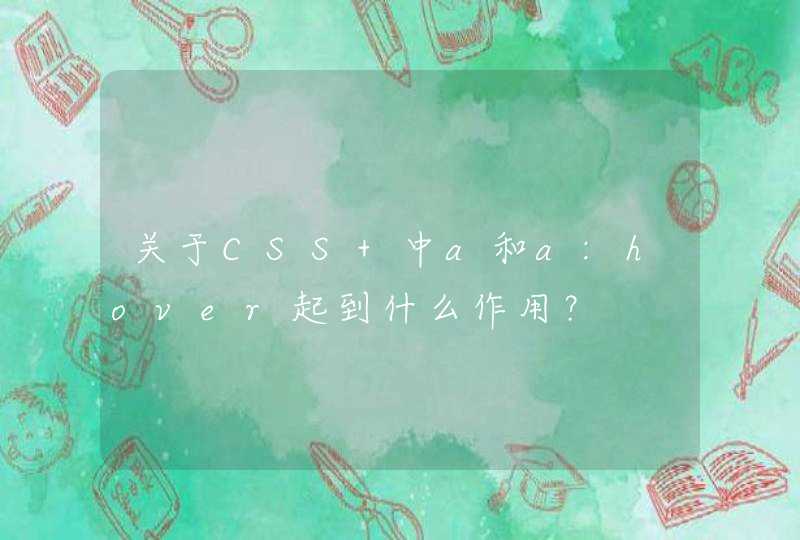
































{
String s = @"<Body>
<div>这里是要取出的文本A <img src=""/>这里是要取出的文本B <a href="">超链接里的文本不取出 </a>这里是要取出的文本C </div>
<body>"
Regex regex = new Regex( "(/?\\w+)[^>]*>([^<]*)<", RegexOptions.IgnoreCase )
MatchCollection ms = regex.Matches( s )
foreach( Match m in ms )
{
string tagName = m.Groups[1].Value.ToLower()
string text = m.Groups[2].Value.Trim()
if( tagName != "a" &&text.Length >0 )
Console.WriteLine( text )
}
}
结果:
这里是要取出的文本A
这里是要取出的文本B
这里是要取出的文本C
请参照以下代码:public static string FilterHtmlTag(string s)
{
//<...>标记正则表达式
return Regex.Replace(s, @"<[^>]*>", delegate(Match match)
{
string v = match.ToString()
//图片,<p>,<br>正则表达式
Regex rx = new Regex(@"^<(p|br|img.*)>$",
RegexOptions.Compiled | RegexOptions.IgnoreCase)//
if (rx.IsMatch(v))
{
return v//保留图片,<p>,<br>
}
else
{
return ""//过滤掉
}
})
}
你只是声明了正则,未做匹配,假定那个字符串叫str,在你上面代码的下面写
foreach (Match m in No_a.Matches(str2))Console.WriteLine(m.Groups[1].Value)//每个m.Groups[1].Value就是你要的内容,自己按需要处理





























