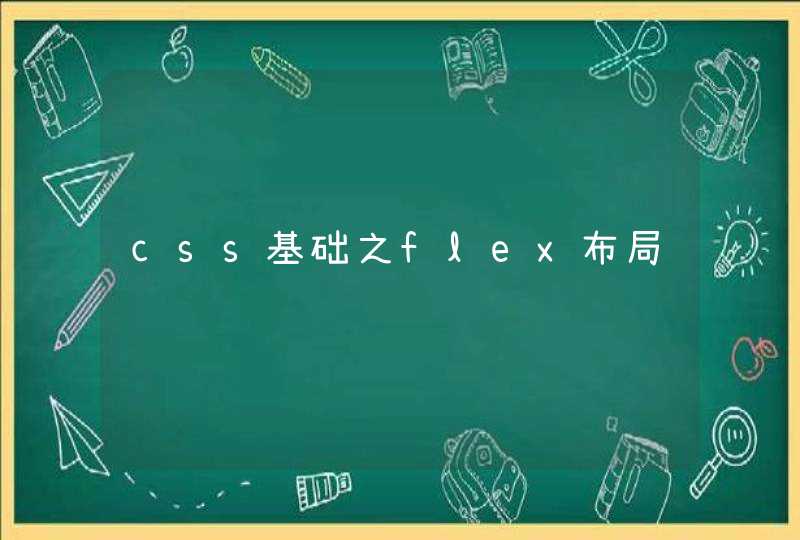







































比如,数学符号 , ,可以直接获得:
escape 将特殊字符 & , < 和 > 替换为HTML安全序列。如果可选的 flags quote 为 True (默认值),则还会翻译引号字符,包括双引号( " )和单引号( ' )字符。
将字符串 s 中的所有命名和数字字符引用 (例如 >, >, >) 转换为相应的 Unicode 字符。此函数使用 HTML 5 标准为有效和无效字符引用定义的规则,以及 HTML 5 命名字符引用列表 。
这个模块定义了一个 HTMLParser 类,为 HTML(超文本标记语言)和 XHTML 文本文件解析提供基础。
class html.parser.HTMLParser(*, convert_charrefs=True) 创建一个能解析无效标记的解析器实例。查找标签(tags)和其他标记(markup)并调用 handler 函数。
用法:
通过调用 self.handle_starttag 处理开始标签,或通过调用 self.handle_startendtag 处理结束标签。标签之间的数据通过以 data 为参数调用 self.handle_data 从解析器传递到派生类(数据可以分成任意块)。如果 convert_charrefs 为 True ,则将字符引用自动转换为相应的 Unicode 字符(并且 self.handle_data 不再拆分成块),否则通过调用带有字符串的 self.handle_entityref 或 self.handle_charref 来传递它们以分别包含命名或数字引用作为参数。如果 convert_charrefs 为 True (默认值),则所有字符引用( script / style 元素中的除外)都会自动转换为相应的 Unicode 字符。
一个 HTMLParser 类的实例用来接受 HTML 数据,并在标记开始、标记结束、文本、注释和其他元素标记出现的时候调用对应的方法。要实现具体的行为,请使用 HTMLParser 的子类并重载其方法。
这个解析器不检查结束标记是否与开始标记匹配,也不会因外层元素完毕而隐式关闭了的元素引发结束标记处理。
下面是简单的 HTML 解析器的一个基本示例,使用 HTMLParser 类,当遇到开始标记、结束标记以及数据的时候将内容打印出来。
输出:
HTMLParser.reset() 重置实例。丢失所有未处理的数据。在实例化阶段被隐式调用。
HTMLParser.feed(data) 填充一些文本到解析器中。如果包含完整的元素,则被处理;如果数据不完整,将被缓冲直到更多的数据被填充,或者 close() 被调用。 data 必须为 str 类型。
HTMLParser.close() 如同后面跟着一个文件结束标记一样,强制处理所有缓冲数据。这个方法能被派生类重新定义,用于在输入的末尾定义附加处理,但是重定义的版本应当始终调用基类 HTMLParser 的 close() 方法。
HTMLParser.getpos() 返回当前行号和偏移值。
HTMLParser.get_starttag_text() 返回最近打开的开始标记中的文本。结构化处理时通常应该不需要这个,但在处理“已部署”的 HTML 或是在以最小改变来重新生成输入时可能会有用处(例如可以保留属性间的空格等)。
下列方法将在遇到数据或者标记元素的时候被调用。他们需要在子类中重载。基类的实现中没有任何实际操作(除了 handle_startendtag() ):
HTMLParser.handle_starttag 这个方法在标签开始的时候被调用(例如: <div id="main">)。 tag 参数是小写的标签名。 attrs 参数是一个 (name, value) 形式的列表,包含了所有在标记的 <> 括号中找到的属性。 name 转换为小写, value 的引号被去除,字符和实体引用都会被替换。比如,对于标签 <a href="https://www.cwi.nl/">,这个方法将以下列形式被调用 handle_starttag('a', [('href', 'https://www.cwi.nl/')]) 。 html.entities 中的所有实体引用,会被替换为属性值。
HTMLParser.handle_endtag(tag) 此方法被用来处理元素的结束标记(例如: </div>)。 tag 参数是小写的标签名。
HTMLParser.handle_startendtag(tag, attrs) 类似于 handle_starttag() , 只是在解析器遇到 XHTML 样式的空标记时被调用( <tag ... />)。这个方法能被需要这种特殊词法信息的子类重载;默认实现仅简单调用 handle_starttag() 和 handle_endtag() 。
HTMLParser.handle_data(data) 这个方法被用来处理任意数据(例如:文本节点和 <script>...</script> 以及 <style>...</style> 中的内容)。
HTMLParser.handle_entityref(name) 这个方法被用于处理 &name 形式的命名字符引用(例如 >),其中 name 是通用的实体引用(例如: 'gt' )。如果 convert_charrefs 为 True,该方法永远不会被调用。
HTMLParser.handle_charref(name) 这个方法被用来处理 NNN 和 NNN 形式的十进制和十六进制字符引用。例如, > 等效的十进制形式为 >,而十六进制形式为 > ;在这种情况下,方法将收到 '62' 或 'x3E' 。如果 convert_charrefs 为 True ,则该方法永远不会被调用。
HTMLParser.handle_comment(data) 这个方法在遇到注释的时候被调用(例如: )。例如, 这个注释会用 ' comment ' 作为参数调用此方法。
Internet Explorer 条件注释(condcoms)的内容也被发送到这个方法,因此,对于 ``,这个方法将接收到 '[if IE 9]>IE9-specific content<![endif]' 。
HTMLParser.handle_decl(decl) 这个方法用来处理 HTML doctype 申明(例如 <!DOCTYPE html>)。 decl 形参为 <!...> 标记中的所有内容(例如: 'DOCTYPE html' )。
HTMLParser.handle_pi(data) 此方法在遇到处理指令的时候被调用。 data 形参将包含整个处理指令。例如,对于处理指令 <?proc color='red'>,这个方法将以 handle_pi("proc color='red'") 形式被调用。它旨在被派生类重载;基类实现中无任何实际操作。
注解: HTMLParser 类使用 SGML 语法规则处理指令。使用 '?' 结尾的 XHTML 处理指令将导致 '?' 包含在 data 中。
HTMLParser.unknown_decl(data) 当解析器读到无法识别的声明时,此方法被调用。 data 形参为 <![...]> 标记中的所有内容。某些时候对派生类的重载很有用。基类实现中无任何实际操作。
因此,我们可以如此定义:
下面介绍如何解析 HTML 文档。
解析一个文档类型声明:
解析一个具有一些属性和标题的元素:
script 和 style 元素中的内容原样返回,无需进一步解析:
解析注释:
解析命名或数字形式的字符引用,并把他们转换到正确的字符(注意:这 3 种转义都是 '>' ):
填充不完整的块给 feed() 执行, handle_data() 可能会多次调用(除非 convert_charrefs 被设置为 True ):
解析无效的 HTML (例如:未引用的属性)也能正常运行:
需要配置啊。比如你用的是apache2,需要指定脚本所在目录为script。然后apache2会通过cgihandler调用你的脚本。另外脚本也要可执行。chmod 777 test.py
修改HTMLTestRunner.py以支持python3+
搜索到的结果整理
修改一: 在python shell里输入 >>>import HTMLTestRunner >>>dir(HTMLTestRunner) 发现不认识StringIO (No module named StringIO)
确实3里面没有这个了,第94行引入的名称要改,改成import io,539行要改成self.outputBuffer = io.BytesIO()
修改二: 运行程序的时候有报错,AttributeError: ‘dict’ object has no attribute ‘has_key’ 发现has_key的又被K掉了
到642行去做修改,if not rmap.has_key(cls): 需要换成 if not cls in rmap: (修改的时候换行、空格等不要改掉原有的格式)
修改三: 运行,继续有报错:’str’ object has no attribute ‘decode’
好像是3里面对字符的操作,decode已经拿掉了。定位一下,报在了772行,ue = e.decode(‘latin-1’),那么不需要decode操作了吧,直接改成 ue = e ,另外766还有类似的uo = o.decode(‘latin-1’),可不动先留着;
打开本地文件需用 fp = open(filename,’wb’),不要再去用file了;关闭该文件可用fp.close()
修改四: 继续运行,发现还是在纠结数据类型的错: output = saxutils.escape(uo+ue), TypeError: can’t concat bytes to str
bytes和str不能直接连起来,那么778行的内容escape(uo+ue) 有一个处理的“笨办法”:都改成str,可修改该处内容为escape(str(uo)+ue)
修改五:(此处是最后一处改动了) 程序已然运行大半,但是最后还是有error: print >>sys.stderr, ‘\nTime Elapsed: %s’ % (self.stopTime-self.startTime) TypeError: unsupported operand type(s) for >>: ‘builtin_function_or_method’ and ‘RPCProxy’
到631行,把print的语句修改掉,改成 print (sys.stderr, ‘\nTime Elapsed: %s’ % (self.stopTime-self.startTime))





























