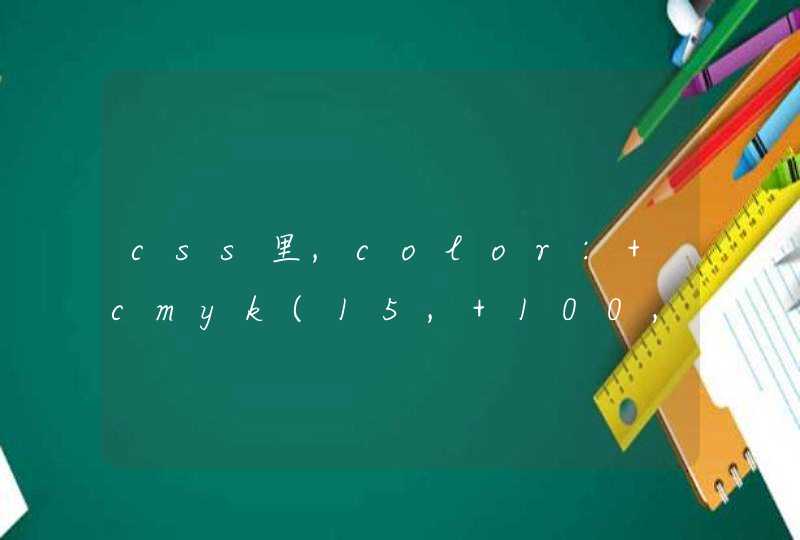本来只想匹配 . ,但是在这里这个点代表了所有字符,于是返回了1 2 3。这个. 就是一个转义表达式。
分别提取含7-9的数字或3-4的数字的字符串
^XX就是以XX开头的意思
当^放在方括号内是取非的意思
2{2,3}是寻找2倍重复了2到3次的意思
2{2,}是寻找2倍重复了大于2次(2到+无穷)的意思
fo+表示+紧跟着的o可以被重复1次或1次以上
大括号也可以起到这样的作用
若想让紧跟在o后面的对fo都起作用,需要小括号
与+用法一致。+表示重复了1次或1次以上,*表示0次或0次以上。
.* 可以匹配任意字符
管道符连接前后,符合其一即会被返回
\\b也可以起到一样的作用,但\\b更灵活,既可以放开头也可以放结尾。(\\b主要是匹配边界)
\的作用就是说明^不是开头的意思,是要去匹配这个符号
对所有的转义符号都适用
您好,最近初学R语言,在R语言读入EXCEL数据格式文件的问题上遇到了困难,经过在网上搜索解决了这一问题,下面归纳几种方法,供大家分享:第一:R中读取excel文件中的数据的路径:
假定在您的电脑有一个excel文件,原始的文件路径是:D:\work\data\1
如果直接把这个路径拷贝到R中,就会出现错误,原因是:
\是escape character(转义符),\\才是真正的\字符,或者用/
因此,在R中有两种方法读取该路径:
1:在R中输入一下路径:D:\\work\\data\\1
2:在R中输入一下路径:D:\\work\\data\\1
第二:R中读取excel文件中的数据的方法:
read.table(),read.csv(),read.delim()直接读取EXCEl文件时,都会遇到一下问题:“在读取‘.xls’的TableHeader时遇到不完全的最后一行”。解决的方法有以下几种:假如文件1.1中是一个6乘以2的矩阵,元素为:
123
224
325
426
527
628
方法1:xls另存为csv格式然后用read.csv:
具体过程如下:
>data<-read.csv("D:\\work\\data\\1.csv")
>data
X1 X23
1 2 24
2 3 25
3 4 26
4 5 27
5 6 28
>data<-read.csv("D:\\work\\data\\1.csv",header = F)
>data
V1V2
1 1 23333
2 224
3 325
4 426
5 527
6 628
>data<-read.csv("D:\\work\\data\\1.csv",header = T)
>data
X1 X23333
1 2 24
2 3 25
3 4 26
4 5 27
5 6 28
也就是说header = T(TURE)是默认的状态,在这默认状态下,输出的data矩阵是一个5乘以2的矩阵,第一行作为了data的名字,如果header = F(FALSE),则会现实原始的矩阵结果。
cmd中%号和双引号输入不能靠转移字符^,, 转义双引号是 三个双引号连在一起 比如:123"456 就是 123"""456 "A""B" 就是 """A""""""B""" 顺便提一下: %号也差不多 转义就是两个百分比:%% 望采纳