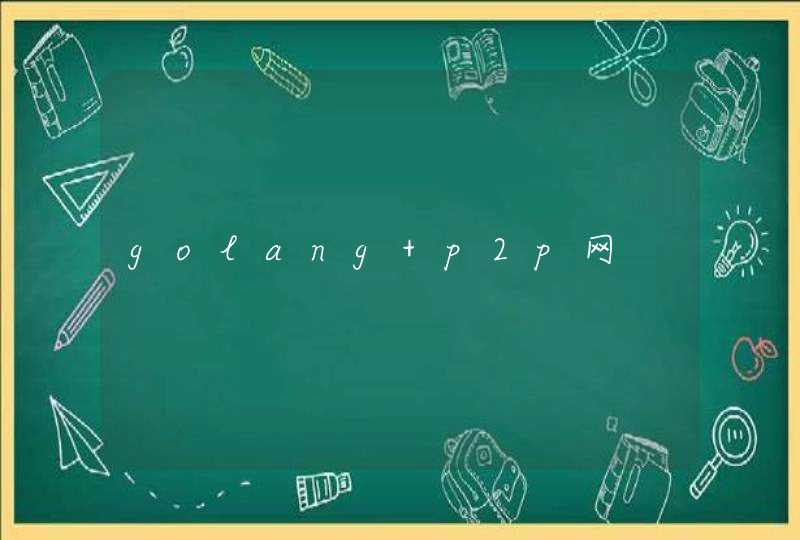'a'<'b'
'a'>'B'
所以首先都变成小写吧。
然后
sorted_string=reduce(lambda
x,y:x>y
and
y+x
or
x+y,lowered_string
)
这样会失去原字符串的大小写。
如果想保留大小写,
让他们等效,恐怕需要专门定义一个函数来比较,
一个lambda搞不定。
------------------
看错了,是排序英文名,也是同样的方法,把每个名字第一字符拿出来比较就行了。
names=['张凤兰', '邓宁', '单桂兰', '李浩', '郭丽丽', '马秀荣', '胡燕', '杨晶', '陈柳', '李辉', '杨春梅', '郭春梅', '陈彬', '姚金凤', '谢正', '王辉', '祁秀芳', '沈红梅', '林凤兰', '彭文', '叶涛', '高 琴', '魏欢', '李海燕', '孔军', '曾宁', '李云', '仇丽娟', '阎淑兰', '杨淑珍', '李丽丽', '李峰', '韩东', '顾丽丽', '周玉 ', '陈博', '何丽娟', '叶利', '陈欣', '张畅', '黄浩', '刘伟', '秦玲', '袁凤英', '蒋娜', '项桂花', '吴建军', '李秀芳', '冯 丽华', '李刚', '白荣']
scorelist=[j for j in range(1,len(names)+1)][::-1]
person=dict(zip(names,scorelist))
person_name=dict(sorted(person.items(),key=lambda x:x[0]))#名字排序
print(f"姓名及名次如下:\n{person_name}\n")
#result=[]
person_score=dict(sorted(person.items(),key=lambda x:x[1]))#名次排序
print("排名前30%名次及姓名如下:")
for k,v in person_score.items():
if v<=0.3*(max(person_score.values())):
print(v,k)
#result.append((v,k))
#print(f"排名前30%名次及姓名如下:\n{dict(result)}")
用sorted函数啊def my_sorted(name1, name2):
return name1 >name2
names = ["afa","dfdf"]
sorted(names, my_sorted)
排序函数自己写,我瞎写的。py2.7的版本
你可以看sorted的接口说明,支持cmp参数,就是一个比较函数。默认是none的。一般问题都可以通过文档找到结果的,希望对你有用