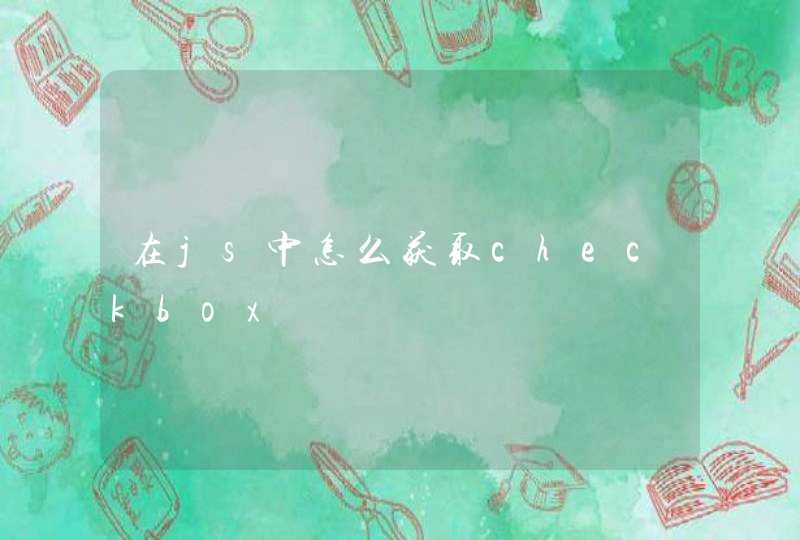f=File.new(File.join("C:","Test.txt"), "w+")
f.puts("I am Jack")
f.puts("Hello World")
文件模式
"r" :Read-only. Starts at beginning of file (default mode).
"r+" :Read-write. Starts at beginning of file.
"w" :Write-only. Truncates existing file to zero length or creates a new file for writing.
"w+" :Read-write. Truncates existing file to zero length or creates a new file for reading and writing.
"a" :Write-only. Starts at end of file if file existsotherwise, creates a new file for writing.
"a+" :Read-write. Starts at end of file if file existsotherwise, creates a new file for reading and writing.
"b" :(DOS/Windows only.) Binary file mode. May appear with any of the key letters listed above
二、读取文件
file=File.open(File.join("C:","Test.txt"),"r")
file.each { |line| print "#{file.lineno}.", line }
file.close
三、新建、删除、重命名文件
File.new( "books.txt", "w" )
File.rename( "books.txt", "chaps.txt" )
File.delete( "chaps.txt" )
四、目录操作
1 创建目录
Dir.mkdir("c:/testdir")
04 #删除目录
05 Dir.rmdir("c:/testdir")
07 #查询目录里的文件
08 p Dir.entries(File.join("C:","Ruby")).join(' ')
10 #遍历目录
11 Dir.entries(File.join("C:","Ruby")).each {
|e| puts e
}
1、ARGV and ARGF
ARGV
ARGV <<"cnblogslink.txt"
#The gets method is a Kernel method that gets lines from ARGV
print while gets
p ARGV.class
ARGF
while line = ARGF.gets
print line
end
2、文件信息查询
#文件是否存在
p File::exists?( "cnblogslink.txt" ) # =>true
#是否是文件
p File.file?( "cnblogslink.txt" ) # =>true
#是否是目录
p File::directory?( "c:/ruby" ) # =>true
p File::directory?( "cnblogslink.txt" ) # =>false
#文件权限
p File.readable?( "cnblogslink.txt" ) # =>true
p File.writable?( "cnblogslink.txt" ) # =>true
p File.executable?( "cnblogslink.txt" ) # =>false
#是否是零长度
p File.zero?( "cnblogslink.txt" ) # =>false
#文件大小 bytes
p File.size?( "cnblogslink.txt" ) # =>74
p File.size( "cnblogslink.txt" ) # =>74
#文件或文件夹
p File::ftype( "cnblogslink.txt" ) # =>"file"
#文件创建、修改、最后一次存取时间
p File::ctime( "cnblogslink.txt" ) # =>Sat Sep 19 08:05:07 +0800 2009
p File::mtime( "cnblogslink.txt" ) # =>Sat Sep 19 08:06:34 +0800 2009
p File::atime( "cnblogslink.txt" ) # =>Sat Sep 19 08:05:07 +0800 2009
3、查找文件
puts "查找目录下所有文件及文件夹"
Dir["c:/ruby/*"].each {|x|
puts x
}
puts "条件查询"
Dir.foreach('c:/ruby') {
|x| puts x if x != "." &&x != ".."
}
puts "查找某一类型文件"
Dir["*.rb"].each {|x|
puts x
}
puts "Open 查询"
Dir.open('c:/ruby') { |d| d.grep /l/ }.each{|x| puts x}
puts "---------------------------"
puts "正则表达式查询"
Dir["c:/ruby/ruby/[rs]*"].each{|x| puts x}
puts "------------------------"
Dir["c:/ruby/[^s]*"].each{|x| puts x}
puts "------------------------"
Dir["c:/ruby/{ruby,li}*"].each{|x| puts x}
puts "------------------------"
Dir["c:/ruby/?b*"].each{|x| puts x}
puts "查找目录及子目录的文件"
require 'find'
Find.find('./') { |path| puts path }
3、查询目录及子目录文件
require "find"
Find.find("/etc/passwd", "/var/spool/lp1", ".") do |f|
Find.prune if f == "."
puts f
end
原型:ref.find( [ aName ]* ) {| aFileName | block }
prune:Skips the current file or directory, restarting the loop with the next entry. If the current file is a directory, that directory will not be recursively entered. Meaningful only within the block associated with Find::find.
4、文件比较 复制等
require 'ftools'
File.copy 'testfile', 'testfile1' » true
File.compare 'testfile', 'testfile1' » true
ruby中判断目录是否存在:File.directory?(argu)
ruby文件操作:使用File类的静态方法,或者File类的实例对象
File类的静态方法
File::atime(filename)
返回指定文件的最后访问时间
1.创建文件夹
Dir.new %%1
Dir::mkdir #不指定目录全名称时,缺省为工作目录
Dir::chdir() 改变当前脚本工作目录
FileUtils.mkdir 'test'
file = File.new("cmd.txt")
file.each do |line|
puts line if line =~ /target/
end
2.创建文件
改变当前根目录
Dir.chdir("/home/guy/sandbox/tmp")
Dir.chroot("/home/guy/sandbox")
Dir.new %%1
#Dir::rmdir #不指定目录全名称时,缺省为工作目录
3.删除文件
改变当前根目录
Dir.chdir("/home/guy/sandbox/tmp")
Dir.chroot("/home/guy/sandbox")
Dir.new %%1
#Dir::rmdir #不指定目录全名称时,缺省为工作目录
4.删除文件夹
#require 'fileutils'
FileUtils.rm_r(%%1)
5.删除一个文件下夹所有的文件夹
Dir::chdir
Dir::pwd属性或者Dir.getwd()
#改变当前脚本工作目录
6.清空文件夹
Dir::chdir %%1 改变当前脚本工作目录
Dir::rmdir #不指定目录全名称时,缺省为工作目录
Dir.new %%1
#require 'ftools'
FileUtils.mkdir 'test'
file = File.new(%%1) #"cmd.txt"
file.each do |line|
puts line if line =~ /target/
end
7.读取文件
#require 'ftools'
File.open(%%1).readlines #'文件名'
#require 'ftools'
arr = IO.readlines(%%1) #"myfile"
lines = arr.size
#puts "myfile has #{lines} lines in it."
#longest = arr.collect {|x| x.length}.max
#puts "The longest line in it has #{longest} characters."
8.写入文件
f=open(%%1,"w")
f.puts(%%2)
9.写入随机文件
#require 'ftools'
file = File.open(%%1,"w")
file.seek(5)
str = file.gets # "fghi"
#require 'ftools'
File.open('文件名')
File.open("cmd.txt","r") do |file|
while line=file.gets
puts line
end
end
puts
file=File.new("cmd.txt","r")
file.each_line do |line|
puts line
end
IO.foreach("cmd.txt") do |line|
puts line if line =~ /target/
puts line if line !~ /target/
end
###
Dir#pos
返回当前子文件指针
Dir#pos=
设置子文件指针
Dir#rewind
设置子文件指针到起始位置
Dir#seek
设置子文件指针
Dir#tell
获取当前指针
10.读取文件属性
#文件中是否有内容,(返回false为有内容,返回true为空)
File.new('文件名').stat.zero?
#文件大小
File.size?('文件名')
flag1 = FileTest::zero?("file1")
flag2 = FileTest::size?("file2")
size1 = File.size("file1")
size2 = File.stat("file2").size
###
File::atime(filename)
返回指定文件的最后访问时间
11.写入属性
12.枚举一个文件夹中的所有文件夹
#require 'ftools'
puts Dir.glob('**/*').each { | file | file.downcase }
#要区分目录和普通文件我们这样使用
file1 = File.new("/tmp")
file2 = File.new("/tmp/myfile")
test1 = file1.directory? # true
test2 = file1.file? # false
test3 = file2.directory? # false
test4 = file2.file? # true
###
遍历目录
Dir.foreach(%%1) { |entry| puts entry}
13.复制文件夹
require "fileutils"
FileUtils.cp %%1,%%2
14.复制一个目录下所有的文件夹到另一个文件夹下
#require 'FileUtils'
list=Dir.entries(%%1)
list.each_index do |x|
FileUtils.cp "#{list[x]}",%%2 if !File.directory?(list[x])
end
15.移动文件夹
#require 'FileUtils'
FileUtils.mv %%1,%%2
16.移动一个目录下所有的文件夹到另一个目录下
#require 'FileUtils'
list=Dir.entries(%%1)
list.each_index do |x|
FileUtils.mv "#{list[x]}",%%2 if !File.directory?(list[x])
end
17.以一个文件夹的框架在另一个目录创建文件夹和空文件
#########################
//文件是否存在
File.exist?('文件名')
flag = FileTest::exist?("LochNessMonster")
flag = FileTest::exists?("UFO")
#########################
require 'rubygems'
require 'ruby-debug'
require "find"
module Cz_dirtools
def mkdirs_to(tar,src=Dir.getwd)
#debugger
if tar.class==NilClass then
puts "PLZ input target directory name..."
return
elsif !FileTest.directory?(tar)#如果tar不是一个目录
puts ("Creating #{File.expand_path(tar)}")
Dir.mkdir("#{File.expand_path(tar)}")#创建tar目录
end
src=if FileTest.directory?(src) then
src#如果src是一个目录名,则返回自身
else
File.dirname(src)#如果src为一个文件名,则返回该文件所在目录
end
#Dir.foreach可以复制目标路径第一层目录结构而不复制子目录
#~ Dir.foreach(src) do |dir|
#~ if FileTest.directory?(dir) &&dir!=tar &&dir!='..' &&dir!='.' then #忽略自身,忽略上级目录"..",忽略本级目录"."
#~ #puts dir
#~ begin
#~ Dir.mkdir("#{File.expand_path(tar)}/#{dir}")
#~ rescue#如果该目录已存在则直接跳过否则创建该目录
#~ end
#~ end
#~ end
#Find.find可以复制目标路径的完整目录结构,包括子目录
dirs=Array.new
Find.find(src) do |dir|
unless !FileTest.directory?(dir) || File.basename(dir)==tar || File.basename(dir)=='..' || File.basename(dir)=='.' || File.basename(dir)==File.basename(src)#忽略自身,忽略上级目录"..",忽略本级目录"."
dirs<<dir
end
end
#puts dirs
dirs.each do |dir|
begin
Dir.mkdir("#{File.expand_path(tar)}/#{dir.gsub(src,'')}")
rescue#如果该目录已存在则直接跳过否则创建该目录
end
end
end
end
require 'rubygems'
require 'ruby-debug'
require "find"
module Cz_dirtools
def mkdirs_to(tar,src=Dir.getwd)
#debugger
if tar.class==NilClass then
puts "PLZ input target directory name..."
return
elsif !FileTest.directory?(tar)#如果tar不是一个目录
puts ("Creating #{File.expand_path(tar)}")
Dir.mkdir("#{File.expand_path(tar)}")#创建tar目录
end
src=if FileTest.directory?(src) then
src#如果src是一个目录名,则返回自身
else
File.dirname(src)#如果src为一个文件名,则返回该文件所在目录
end
#Dir.foreach可以复制目标路径第一层目录结构而不复制子目录
#~ Dir.foreach(src) do |dir|
#~ if FileTest.directory?(dir) &&dir!=tar &&dir!='..' &&dir!='.' then #忽略自身,忽略上级目录"..",忽略本级目录"."
#~ #puts dir
#~ begin
#~ Dir.mkdir("#{File.expand_path(tar)}/#{dir}")
#~ rescue#如果该目录已存在则直接跳过否则创建该目录
#~ end
#~ end
#~ end
#Find.find可以复制目标路径的完整目录结构,包括子目录
dirs=Array.new
Find.find(src) do |dir|
unless !FileTest.directory?(dir) || File.basename(dir)==tar || File.basename(dir)=='..' || File.basename(dir)=='.' || File.basename(dir)==File.basename(src)#忽略自身,忽略上级目录"..",忽略本级目录"."
dirs<<dir
end
end
#puts dirs
dirs.each do |dir|
begin
Dir.mkdir("#{File.expand_path(tar)}/#{dir.gsub(src,'')}")
rescue#如果该目录已存在则直接跳过否则创建该目录
end
end
end
end
18.复制文件
#require 'FileUtils'
FileUtils.cp %%1, %%2
19.复制一个目录下所有的文件到另一个目录
#require 'FileUtils'
list=Dir.entries(%%1)
list.each_index do |x|
FileUtils.cp "#{list[x]}",%%2 if !File.directory?(list[x])
end
20.提取扩展名
21.提取文件名
%%2 = File.basename(%%1)
22.提取文件路径
%%2 = File.dirname(%%1)
23.替换扩展名
24.追加路径
25.移动文件
26.移动一个文件夹下所有文件到另一个目录
#require 'FileUtils'
list=Dir.entries(%%1)
list.each_index do |x|
FileUtils.mv "#{list[x]}",%%2 if !File.directory?(list[x])
end
27.指定目录下搜索文件
#require "find"
def findfiles(dir, name)
list = []
Find.find(dir) do |path|
Find.prune if [".",".."].include? path
case name
when String
list << path if File.basename(path) == name
when Regexp
list << path if File.basename(path) =~ name
else
raise ArgumentError
end
end
list
end
findfiles %%1,%%2 #"/home/hal", "toc.txt"
28.打开对话框
29.文件分割
逐字节对文件进行遍历
可以使用each_byte方法,如果你想要转换byte到字符的话使用chr方法:
file = File.new("myfile")
e_count = 0
file.each_byte do |byte|
e_count += 1 if byte == ?e
end
30.文件合并
逐字节对文件进行遍历
可以使用each_byte方法,如果你想要转换byte到字符的话使用chr方法:
file = File.new("myfile")
e_count = 0
file.each_byte do |byte|
e_count += 1 if byte == ?e
end
31.文件简单加密
32.文件简单解密
33.读取ini文件属性
34.合并一个文件下所有的文件
35.写入ini文件属性
36.获得当前路径
File.dirname($0)
37.读取XML数据库
38.写入XML数据库
39.ZIP压缩文件
#require 'rubygems'
#require 'zip/zipfilesystem'
Zip::ZipFile.open(%%1, Zip::ZipFile::CREATE) do |zip| #'zipfile.zip'
zip.file.open('file1', 'w') { |f| f <<'This is file 1.' }
zip.dir.mkdir('sub_dir')
zip.file.open('sub_dir/file2', 'w') { |f| f <<'This is file 2.' }
end
40.ZIP解压缩
41.获得应用程序完整路径
42.ZIP压缩文件夹
#require 'rubygems'
#require 'zip/zipfilesystem'
def compress
Zip::ZipFile.open 'zipfile.zip', Zip::ZipFile::CREATE do |zip|
add_file_to_zip('dir', zip)
end
end
def add_file_to_zip(file_path, zip)
if File.directory?(file_path)
Dir.foreach(file_path) do |sub_file_name|
add_file_to_zip("#{file_path}/#{sub_file_name}", zip) unless sub_file_name == '.' or sub_file_name == '..'
end
else
zip.add(file_path, file_path)
end
end
add_file_to_zip %%1,%%2
43.递归删除目录下的文件
#require 'ftools'
file_path = String.new
file_path="D:"
if File.directory? file_path
Dir.foreach(file_path) do |file|
if file!="." and file!=".."
puts "File:"+file
end
end
end
44.验证DTD
45.Schema 验证
46.Grep
#!/usr/bin/env ruby
# Grep with full regexp-functionality via ruby
if ARGV.shift == "-p"
pattern = Regexp.new(ARGV.shift)
else
puts "Please give me a pattern with the '-p' option"
exit
end
ARGV.each do |filename|
File.open(filename) do |file|
file.each do |line|
puts "#{filename} #{file.lineno.to_s}: #{line}" if
pattern.match(line)
end
end
end
Using it via: rgrep -p '/delete /i' *.php does not match anything, but
this
#!/usr/bin/env ruby
# Grep with full regexp-functionality via ruby
if ARGV.shift == "-p"
pattern = Regexp.new(ARGV.shift)
else
puts "Please give me a pattern with the '-p' option"
exit
end
ARGV.each do |filename|
File.open(filename) do |file|
file.each do |line|
puts "#{filename} #{file.lineno.to_s}: #{line}" if /delete
/i.match(line)
end
end
end
47.直接创建多级目录
#require "fileutils"
FileUtils.makedirs(%%1)
48.批量重命名
49.文本查找替换 ReplaceText
50.文件关联
51.操作Excel文件
52.设置JDK环境变量
53.选择文件夹对话框
54.删除空文件夹
55.发送数据到剪贴板
56.从剪贴板中取数据
57.获取文件路径的父路径
58.创建快捷方式 CreateShortCut
59.弹出快捷菜单
60.文件夹复制到整合操作
61.文件夹移动到整合操作
62.目录下所有文件夹复制到整合操作
63.目录下所有文件夹移动到整合操作
64.目录下所有文件复制到整合操作
65.目录下所有文件移动到整合操作
66.对目标压缩文件解压缩到指定文件夹
67.创建目录副本整合操作
68.打开网页
69.删除空文件夹整合操作
70.获取磁盘所有分区后再把光驱盘符去除(用"\0"代替),把结果放在数组allfenqu[] 中,数组中每个元素代表一个分区盘符,不包括 :\\ 这样的路径,allfenqu[]数组开始时存放的是所有盘符。
当我用这样的代码测试结果是正确的,光驱盘符会被去掉:
CString root//root代表盘符路径
for(i=0i<20i++) //0-20代表最大的盘符数
{
root.Format("%c:\\",allfenqu[i])
if(GetDriveType(root)==5)
allfenqu[i]='\0'
}
但我用这样的代码时结果却无法去掉光驱盘符,allfenqu[]中还是会包含光驱盘符:
CString root
for(i=0i<20i++)
{
root=allfenqu[i]+":\\"
if(GetDriveType(root)==5)
allfenqu[i]='\0'
}
本文在Windows7下测试成功。安装和设置Git
下载Git for
Windows,采用默认安装,安装完成后就可以在本地使用Git了。
但要将内容放到Github上,必须先在Github网站上注册个账户,然后在本机使用Git创建SSH Key。操作如下:
在Git Bash上输入命令:
ssh-keygen -C "[email protected]" -t rsa
Note: “[email protected]”需要更换成你在Github上注册的Email地址或者是Username
这样会在用户目录(C:\Users\用户名)下产生一个.ssh文件夹,里面为对应的SSH
Keys,其中id_rsa.pub是Github需要的SSH公钥文件。
到c:\Users\用户名\.ssh\目录找到id_rsa.pub(可能位置不一定对,但是确认是以.pub结尾的文件),并用记事本打开复制全部内容。
Note:建议私钥公钥的名称最好写成"id_rsa",这样连接Github的时候会找这个文件,如果文件名已定,之后改名也行。
在github网站选择“Account Settings”>>“SSH Public Keys”>>“Add another
public key”,将刚才复制的内容粘贴到key文本框内。
这样就可以直接使用Git和GitHub了。
Note:建议在Git Bash中输入“ssh -v [email protected]”测试能够正常连接github
安装Ruby环境
下载RubyInstaller和DevKit。
因为Octopress需要的Ruby版本为1.9.2,所以选rubyinstaller-1.9.2-p290.exe,DevKit-tdm-32-4.5.2-20111229-1559-sfx.exe。
先安装RubyInstaller,然后解压缩DevKit(路径中不能有中文)。
在“Start Command Prompt with Ruby”命令行中进入DevKit解压缩的目录,然后运行以下命令:
ruby dk.rb init
ruby dk.rb install
gem install rdiscount --platform=ruby
如果安装成功,就可以使用一些Ruby的工具了,也为后面搭建博客提供了基础环境。
安装Octopress
先通过Git从Github上克隆一份Octopress(在Git Bash上输入命令)
git clone git://github.com/imathis/octopress.git octopress
然后安装一些依赖的工具(后面都是在Start Command Prompt with Ruby中输入)
cd octopress
ruby --version # Should report Ruby 1.9.2
gem install bundler
bundle install
安装Octopress默认的Theme
rake install
配置Octopress
将octopress的文件夹下的_config.yml的编码改成UTF-8:
保存(或另存为)时选择编码格式为UTF-8
修改_config.yml,批改url、title、subtitle、author等等。
到Ruby的安装目次\lib\ruby\gems\1.9.1\gems\jekyll-0.11.2\lib\jekyll\找到convertible.rb这个文件,批改self.content
= File.read(File.join(base, name))为self.content = File.read(File.join(base,
name), :encoding =>"utf-8")。
写博文
最简单的方式:复制octopress\source\_posts下某个文件,例如2012-07-30-the-first-post.markdown,修改文件名和文件中的内容
或者,命令行中输入rake
new_post["title"],会创建一个新的Post,新文件在source/_post下,文件名如下面的格式:2012-07-31-title.markdown。该文件可以直接打开修改。
写文章时,可以使用Markdown和Octopress
Plugins等工具对内容进行格式排版。
预览效果
在修改设置或者写完文章后,想看看具体效果,可以通过如下命令来完成:
rake generate
rake preview
将博客部署到Github上
在预览的效果符合自己的预期后,就可以通过如下命令将内容部署到Github上了。
如果是第一次部署,需要在Github上创建一个username.github.com的repository
在github网站选择“Create a New Repo”,如图
填写对应的内容即可
note:Repository
name填写username.github.com,username一定要和github的username一致,建好的博客代表的是你这个github账户的主页即page
配置octopress与github的连接:
进入Octopress目录:
rake setup_github_pages
按照提示填入你的github项目网址,比如:
[email protected]:Username/yourname.github.com.git
note:可以按照上面的修改,也可以在github的项目页中找地址
分发到github上:
rake deploy
第一次运行时,会询问是否建立对github的授权,输入:yes。然后将站点更新的内容推送到github上。
补充一点:
最后的但并不是最重要的,我们需要将修改的日志同步到github上,因此下面的3个命令也是必须的。
git status
git add .
git commit -m 'your message'
git push origin source
大功告成!