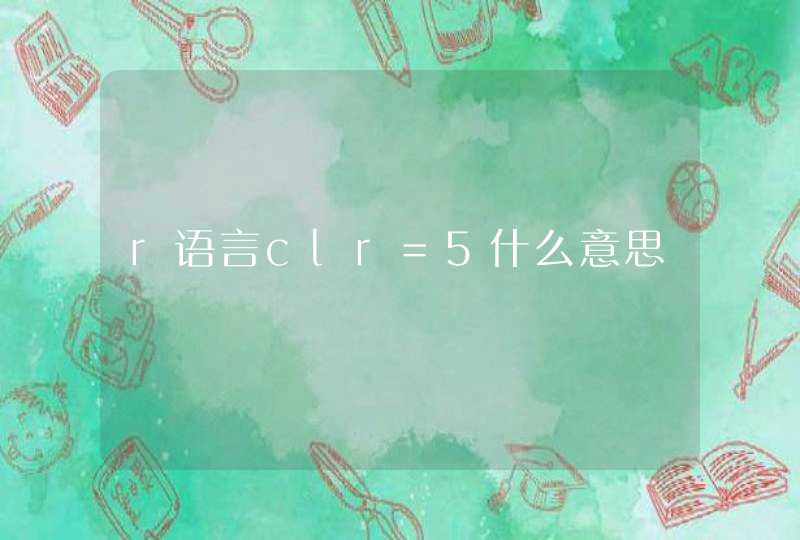,第1张")
本篇教程就让我们来学习如何绘制右图这种“对称散点图”,展示组间差异基因表达格局。
示例文件“gene_diff.txt”是一组基因差异表达分析结果,记录了处理组(treat)和对照组(control)间表达显著不一致的基因,鉴定标准为p<0.01以及|log2 Fold Change|≥1。
其中,gene_id为基因名称;control和treat代表了两组中基因的平均表达值;log2FoldChange即log2转化后的基因表达差异倍数;pvalue是差异基因显著性p值;diff为根据p<0.01以及|log2 Fold Change|≥1筛选的差异基因,该列中“up”为上调,“down”为下调,“none”为非差异基因。
接下来通过该示例文件,展示使用R语言绘制差异基因表达“对称散点图”过程。
首先对数据做一些预处理。
例如,基因表达值数量级相差过大,取个对数转换;基因名称按是否为差异基因作个排序,避免后续作图时被不显著的基因点遮盖,即排序的目的是让这些显著基因的点都位于图的上方。
下来就可以使用预处理后的数据作图了。
第一种类型是将基因按上调、下调或不显著类型着色,便于从图中辨认差异基因。我们使用ggplot2的方法绘制差异基因散点图。
两个坐标轴分别代表了处理组(treat)和对照组(control),图中的点代表各基因在两组中的平均表达值(已经作了log转换)。treat组和control组相比,上调基因以红色表示,下调基因以绿色表示。图中的虚线代表了|log2FC|=1时的阈值线。
在该图中,我们可以很轻松地观察差异基因整体分布状态和数量比较的信息。
上图中没有将p值信息展示出。因此另一种思路是,颜色代表p值,这样就可以在图中获得一个渐变梯度。同样使用ggplot2的方法绘制,和上述过程相比仅在颜色指定上存在区别。
类似上图,两个坐标轴分别代表了处理组(treat)和对照组(control),图中的点代表各基因在两组中的平均表达值(已经作了log转换),图中的虚线代表了|log2FC|=1时的阈值线。
和上图不同点在于,此时基因按显著性p值着色,从不显著>显著展示以蓝色>红色渐变,就获得了一种梯度信息。这样可以很方便地看出,在两组中的表达值差异越大的基因,p值越小,二者趋势是一致的,重在描述了差异倍数和p值的关系。
[1]Anders S, Huber W. Differential expression analysis for sequence count data. Genome Biol . 201011(10):R106. doi:10.1186/gb-2010-11-10-r106
#b站视频——R语言入门与数据分析
#内置数据集
#固定格式的数据(矩阵、数据框或一个时间序列等)
#统计建模、回归分析等试验需要找合适的数据集
#R内置数据集,存储在,通过
help(package="datasets")
#通过data函数访问这些数据集
data()
#得到新窗口 前面:数据集名字 后面:内容
#包含R所有用到的数据类型,包括:向量、矩阵、列表、因子、数据框以及时间序列等
#直接输入数据集的名字就可以直接使用这些数据集
#输出一个向量
rivers
#是北美141条河流长度
#这些数据集的名字都是内置的,一般我们在给变量命名时最好不要重复
#否则数据集在当前对话中会被置换掉
#例如
rivers<-c(1,2,3)
rivers
#不过影响不大
#再使用data函数重新加载这个数据集就可以了
data("rivers")
rivers
#一些常用内置数据集
#默认介绍页面只有名字和介绍,并没有给出数据分类
#哪些是向量、矩阵、数据框等?
#查看数据集除了直接敲数据集名字显示数据之外
#还可以使用help函数查看每个数据集具体的内容
help("mtcars")
euro
#欧元汇率,长度为11,每个元素都有命名
#输出向量的属性信息
names(euro)
#将5个数据构成一个数据框
向量
state.abb #美国50个州的双字母缩写
state.area #美国50个州的面积
state.name #美国50个州的全称
因子
state.division #美国50个州的分类,9个类别
state.region #美国50个州的地理分类
#
state<-data.frame(state.name,state.abb,state.area,state.division,state.region)
state
state.x77 #美国50个州的八个指标
state.x77
VADeaths #1940年弗吉尼亚州死亡率(每千人)
volcano #某火山区的地理信息(10米×10米的网格)
WorldPhones #8个区域在7个年份的电话总数
iris3 #3种鸢尾花形态数据
#以上矩阵→适合画热图
heatmap(volcano)
#这里只是作为一个演示,还需要对这个图进行一些调整
#更复杂的数据结构
Titanic #泰坦尼克乘员统计,是一个数组
UCBAdmissions #伯克利分校1973年院系、录取和性别的频数
crimtab #3000个男性罪犯左手中指长度和身高关系
HairEyeColor #592人头发颜色、眼睛颜色和性别的频数
occupationalStatus #英国男性父子职业联系
#类矩阵
eurodist #欧洲12个城市的距离矩阵,只有下三角部分
Harman23.cor #305个女孩八个形态指标的相关系数矩阵
Harman74.cor #145个儿童24个心理指标的相关系数矩阵
#R中内置最多的数据集——数据框
cars #1920年代汽车速度对刹车距离的影响
iris #3种鸢尾花形态数据
mtcars #32辆汽车在11个指标上的数据
rock #48块石头的形态数据
sleep #两药物的催眠效果
swiss #瑞士生育率和社会经济指标
trees #树木形态指标
USArrests #美国50个州的四个犯罪率指标
women #15名女性的身高和体重
#列表
state.center #美国50个州中心的经度和纬度
#类数据框
Orange #桔子树生长数据
#时间序列数据,和数据框类似,不同的是具有时间序列的顺序,是数据分析中非常常见的格式
#能反映出变化情况以及变化的趋势等
#因此有很多专门的方法用于时间序列的数据分析
co2 #1959-1997年每月大气co2浓度(ppm)
presidents #1945-1974年每季度美国总统支持率
uspop #1790–1970美国每十年一次的人口总数(百万为单位)
#除了内置数据集之外,许多R扩展包中也内置了很多数据集
#这些数据集作为扩展包的函数使用的案例
#加载R包之后这些数据集也同样被加载进来
#例如MASS包中的Cars93数据
#包含了27个变量,是1993年93辆汽车的型号指标
install.packages("MASS")
library("MASS")
help("Cars93")
#使用data函数在参数package中等于对应R包的名字,即可列出每个R包中包含的数据集
#ex
data(package="MASS")
#显示R中所有可用的数据集
data(package=.packages(all.available = TRUE))
#不加载R包使用其中的数据集
data(Chile,package="car")
Chile
#>data(Chile,package="car")
#Warning message:
# In data(Chile, package = "car") : data set ‘Chile’ not found
#>Chile
#Error: object 'Chile' not found
install.packages("car")
library("car")
help("Chile")