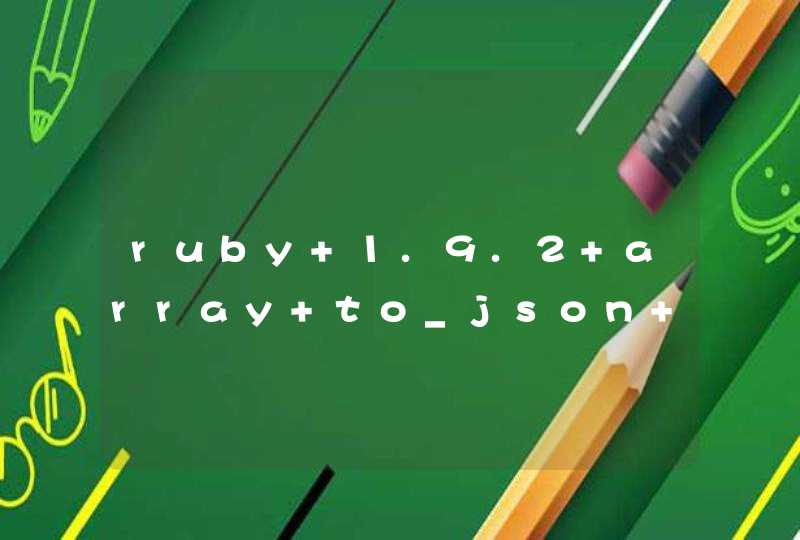d1 <- do.call(cbind, lapply(lapply(d, unlist), length<- , max(lengths(d))))
lapply(x,fun),lapply接收两个值,x为向量或列表,fun是方法,这个函数的意思是将fun方法作用到x的每个元素,返回一个与x相同长度的列表
unlist函数接收一个列表,unlist将其简化为一个包含列表中所有原子成分的向量
外面嵌套的那层lapply函数,是将每个向量元素的长度设定为最长的那个长度,缺失值用NA补齐
cbind是按列合并向量,如果两列数量不一样会自动重复短的那列
do.call函数与lapply函数功能类似,但有一点不一样
lapply()为列表中的每个元素应用一个给定的函数,所以会有几个函数调用。
do.call()将给定的函数作为一个整体应用于列表,所以只有一个函数调用。
详细差别见 http://www.dovov.com/rlapplydo-call.html
数据框(data.frame)是R中最常处理的数据结构。
函数:data.frame(col1,col2,col3,....,row.name=NULL, check.rows = FALSE, check.names=TRUE, stringsAsFactors = default.stringsAsFactors())
其中的列向量col1, col2, col3,...可为任何类型(如字符型、数值型或逻辑型),每一列的名称可由函数names指定;
row.name用于指定各行(样本)的名称,默认没有名称,使用从1开始自增的序列来标识每一行;
check.rows用于用来检查行的名称和数量是否一致,默认为FALSE;
check.names来检查变量(列)的名称是否唯一且符合语法,默认为TRUE;
stringsAsFactors用来描述是否将字符型向量自动转换为因子,默认转换,若不改变的话使用stringsAsFactors = FALSE来指定即可。
每一列数据的模式必须唯一,不过你却可以将多个模式的不同列放到一起组成数据框。
先构建向量,再组成数据框。
直接用data.frame函数构建数据框。
R语言的下标索引是从1开始的,且下标索引为负数的话表示删除某个元素。
[] 可进行索引,括号内对应的是[行下标, 列下标]。
[1] 1 2 3 4 5 6 7 8
[1] "four"
[1] 1 2 3 4 5 6 7 8
[1] "four"
[1] 1 2 3 4 5 6 7 8
[1] "one" "two" "three"
attach、detach和with()
函数attach()可将数据框添加到R的搜索路径中。
函数detach()将数据框从搜索路径中移除。
函数attach()和detach()最好在你分析一个单独的数据框,并且不太可能有多个同名对象时使用。
with()就是把所有操作都限制在数据框上。
The following objects are masked by .GlobalEnv:
[1] 1 2 3 4 5 6 7 8
[1] "n1" "n2" "n3" "n4" "n5" "n6" "n7" "n8"
[1] 8
[1] 3
[1] 8
[1] "name""values" "values2"
[1] "r1" "r2" "r3" "r4" "r5" "r6" "r7" "r8"
[1] 8 3
[1] "data.frame"
[1] "numeric"
[1] "character"
Length:8 Min. :1.00 Min. :1.00
Class :character 1st Qu.:2.75 1st Qu.:2.75
Mode :character Median :4.50 Median :4.50
Mean :4.50 Mean :4.50
3rd Qu.:6.25 3rd Qu.:6.25
Max. :8.00 Max. :8.00
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE