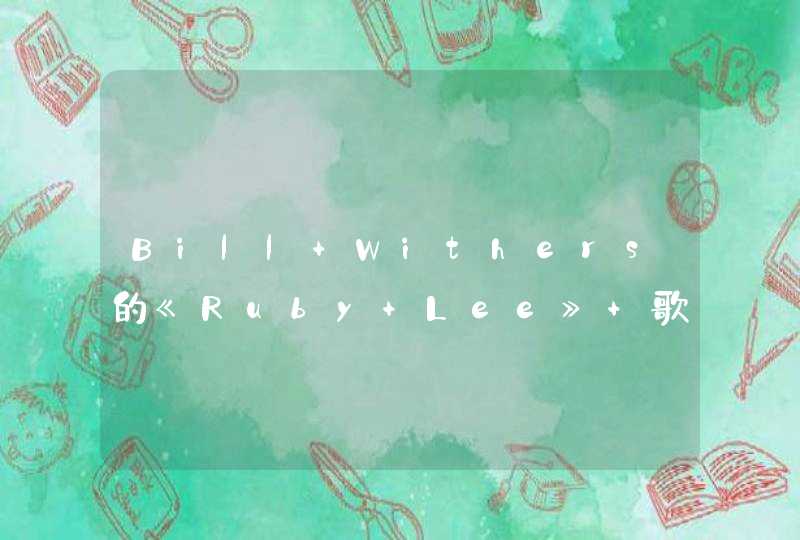file_names<- list.files("D:\\工作\\190304\\电子券")
path <- c("D:\\工作\\190304\\电子券\\")
for (i in 1:length(file_names)) {
name<-gsub(".csv","",file_names[i])
assign(name,
read.csv(paste0(path,file_names[1]),
header = TRUE, stringsAsFactors = FALSE))
}
bd_mob0 <- data.frame()
bd_mob1 <- data.frame()
for (i in 1:length(file_names)){
excel_path <- paste0(path1,file_names[i])
sheet_name <- excel_sheets(excel_path)[6]
bd_mob0 <- cbind(read_excel(excel_path,sheet = sheet_name, skip =3),
账期 = substr(file_names[i],18,25)) # 加入账期
bd_mob1 <- rbind(bd_mob1, bd_mob0)
}
杀杀前两天一个同学问了一个批量读数据(文件)的问题
感觉现在分析测序数据的话,在R中一次性读取多个文件的功能还是挺需要用到的
决定总结一下下
总不能写n行read.csv…balabala…去读取,那太麻烦了
于是决定使用批量读数据
首先我们要获取这个文件夹里所有的文件名字以便读取
接下来我们需要构建读文件的路径
ps: 在做这种批量操作时还是有必要先花时间测试一个样本是否能够成功,然后再去做批量的循环,这样也能方便自己找bug
因此我们先试着读取一个文件
这里因为例子中的文件格式比较特殊,所以使用的读取函数是read.delim,如果是.csv或.txt等格式,也可以替换成read.csv, read.table等函数。
好了测试通过,接下来开始批量读文件
需要注意的是,合并文件的时候,需要注意你是要取所有文件中行名的交集还是并集,或者最后你是否有一个统一的行名来规整所有文件。(当然如果你确定每个文件的行名都是相同的,就可以直接cbind),我遇到过需要取交集的情况,可以写一个循环对每个文件的行名做交集,用最终的交集文件去match出所有你要的行然后合并。
但是这个例子中,有的文件的行名是1-4000,有的是5000-8000,存在非常大的差异,而需求是最后整合成一个行名为0-8000的矩阵,因此我先建立一个0-8000的列作为行名,把每个文件和这列进行一个match操作,然后未match到的填充为0。
其实没有很难的部分,主要是需要读取文件夹中的所有文件名,然后循环读取就行了。