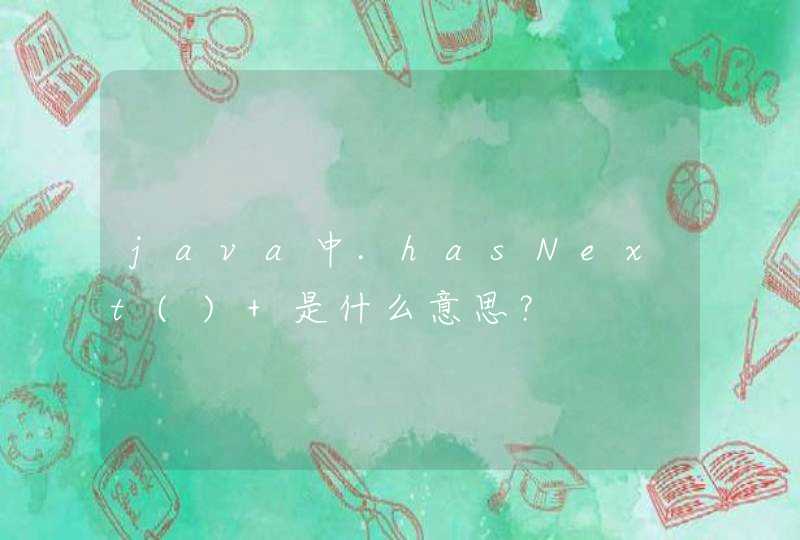总体来说golang的map是hashmap,是使用数组+链表的形式实现的,使用拉链法消除hash冲突。
golang的map由两种重要的结构,hmap和bmap(下文中都有解释),主要就是hmap中包含一个指向bmap数组的指针,key经过hash函数之后得到一个数,这个数低位用于选择bmap(当作bmap数组指针的下表),高位用于放在bmap的[8]uint8数组中,用于快速试错。然后一个bmap可以指向下一个bmap(拉链)。
Golang中map的底层实现是一个散列表,因此实现map的过程实际上就是实现散表的过程。在这个散列表中,主要出现的结构体有两个,一个叫 hmap (a header for a go map),一个叫 bmap (a bucket for a Go map,通常叫其bucket)。这两种结构的样子分别如下所示:
hmap :
图中有很多字段,但是便于理解map的架构,你只需要关心的只有一个,就是标红的字段: buckets数组 。Golang的map中用于存储的结构是bucket数组。而bucket(即bmap)的结构是怎样的呢?
bucket :
相比于hmap,bucket的结构显得简单一些,标红的字段依然是“核心”,我们使用的map中的key和value就存储在这里。“高位哈希值”数组记录的是当前bucket中key相关的“索引”,稍后会详细叙述。还有一个字段是一个指向扩容后的bucket的指针,使得bucket会形成一个链表结构。例如下图:
由此看出hmap和bucket的关系是这样的:
而bucket又是一个链表,所以,整体的结构应该是这样的:
哈希表的特点是会有一个哈希函数,对你传来的key进行哈希运算,得到唯一的值,一般情况下都是一个数值。Golang的map中也有这么一个哈希函数,也会算出唯一的值,对于这个值的使用,Golang也是很有意思。
Golang把求得的值按照用途一分为二:高位和低位。
如图所示,蓝色为高位,红色为低位。 然后低位用于寻找当前key属于hmap中的哪个bucket,而高位用于寻找bucket中的哪个key。上文中提到:bucket中有个属性字段是“高位哈希值”数组,这里存的就是蓝色的高位值,用来声明当前bucket中有哪些“key”,便于搜索查找。 需要特别指出的一点是:我们map中的key/value值都是存到同一个数组中的。数组中的顺序是这样的:
并不是key0/value0/key1/value1的形式,这样做的好处是:在key和value的长度不同的时候,可 以消除padding(内存对齐)带来的空间浪费 。
现在,我们可以得到Go语言map的整个的结构图了:(hash结果的低位用于选择把KV放在bmap数组中的哪一个bmap中,高位用于key的快速预览,用于快速试错)
map的扩容
当以上的哈希表增长的时候,Go语言会将bucket数组的数量扩充一倍,产生一个新的bucket数组,并将旧数组的数据迁移至新数组。
加载因子
判断扩充的条件,就是哈希表中的加载因子(即loadFactor)。
加载因子是一个阈值,一般表示为:散列包含的元素数 除以 位置总数。是一种“产生冲突机会”和“空间使用”的平衡与折中:加载因子越小,说明空间空置率高,空间使用率小,但是加载因子越大,说明空间利用率上去了,但是“产生冲突机会”高了。
每种哈希表的都会有一个加载因子,数值超过加载因子就会为哈希表扩容。
Golang的map的加载因子的公式是:map长度 / 2^B(这是代表bmap数组的长度,B是取的低位的位数)阈值是6.5。其中B可以理解为已扩容的次数。
当Go的map长度增长到大于加载因子所需的map长度时,Go语言就会将产生一个新的bucket数组,然后把旧的bucket数组移到一个属性字段oldbucket中。注意:并不是立刻把旧的数组中的元素转义到新的bucket当中,而是,只有当访问到具体的某个bucket的时候,会把bucket中的数据转移到新的bucket中。
如下图所示:当扩容的时候,Go的map结构体中,会保存旧的数据,和新生成的数组
上面部分代表旧的有数据的bucket,下面部分代表新生成的新的bucket。蓝色代表存有数据的bucket,橘黄色代表空的bucket。
扩容时map并不会立即把新数据做迁移,而是当访问原来旧bucket的数据的时候,才把旧数据做迁移,如下图:
注意:这里并不会直接删除旧的bucket,而是把原来的引用去掉,利用GC清除内存。
map中数据的删除
如果理解了map的整体结构,那么查找、更新、删除的基本步骤应该都很清楚了。这里不再赘述。
值得注意的是,找到了map中的数据之后,针对key和value分别做如下操作:
1
2
3
4
1、如果``key``是一个指针类型的,则直接将其置为空,等待GC清除;
2、如果是值类型的,则清除相关内存。
3、同理,对``value``做相同的操作。
4、最后把key对应的高位值对应的数组index置为空。
// 先声明mapvar m1 map[string]string
// 再使用make函数创建一个非nil的map,nil map不能赋值
m1 = make(map[string]string)
// 最后给已声明的map赋值
m1["a"] = "aa"
m1["b"] = "bb"
// 直接创建
m2 := make(map[string]string)
// 然后赋值
m2["a"] = "aa"
m2["b"] = "bb"
// 初始化 + 赋值一体化
m3 := map[string]string{
"a": "aa",
"b": "bb",
}
望采纳。。
// ==========================================
// 查找键值是否存在
if v, ok := m1["a"]ok {
fmt.Println(v)
} else {
fmt.Println("Key Not Found")
}
// 遍历map
for k, v := range m1 {
fmt.Println(k, v)
}
sync.Map是1.9才推荐的并发安全的map,除了互斥量以外,还运用了原子操作,所以在这之前,有必要了解下 Go语言——原子操作
go1.10\src\sync\map.go
entry分为三种情况:
从read中读取key,如果key存在就tryStore。
注意这里开始需要加锁,因为需要操作dirty。
条目在read中,首先取消标记,然后将条目保存到dirty里。(因为标记的数据不在dirty里)
最后原子保存value到条目里面,这里注意read和dirty都有条目。
总结一下Store:
这里可以看到dirty保存了数据的修改,除非可以直接原子更新read,继续保持read clean。
有了之前的经验,可以猜测下load流程:
与猜测的 区别 :
由于数据保存两份,所以删除考虑:
先看第二种情况。加锁直接删除dirty数据。思考下貌似没什么问题,本身就是脏数据。
第一种和第三种情况唯一的区别就是条目是否被标记。标记代表删除,所以直接返回。否则CAS操作置为nil。这里总感觉少点什么,因为条目其实还是存在的,虽然指针nil。
看了一圈貌似没找到标记的逻辑,因为删除只是将他变成nil。
之前以为这个逻辑就是简单的将为标记的条目拷贝给dirty,现在看来大有文章。
p == nil,说明条目已经被delete了,CAS将他置为标记删除。然后这个条目就不会保存在dirty里面。
这里其实就跟miss逻辑串起来了,因为miss达到阈值之后,dirty会全量变成read,也就是说标记删除在这一步最终删除。这个还是很巧妙的。
真正的删除逻辑:
很绕。。。。