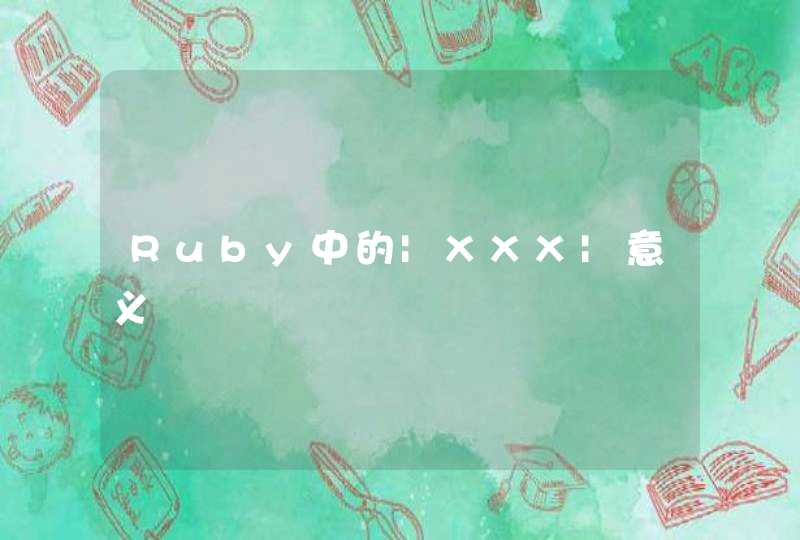我写了这个代码,python2.6+windows xp测试通过。
希望能帮到你~
===================================================
a=[] #初始化要用到的列表a,用于记录原始行信息
b=[] #初始化要用到的列表b,用于记录结果数据,由两项构成。前一项为行信息如“小明:90”,后一项为该行对应的出现次数如2
f1=file("1.txt", "r") #打开1.txt文件
for line in f1:
a.append(line) #将1.txt文件每一行作为一个元素,存入列表a
f1.close
for n in a: #遍历a中每一项(记为n),即1.txt中每一行
flag=1
for i in range(0,len(b)):
if n == b[i][0]: #n与列表b中的每一项对比,如果有相等的:
b[i][1]=b[i][1]+1 #那么对应的出现计数加1
flag=0
break
if flag==1: #如果前面的比对没有一个相等的,即该行是第一次出现:
b.append([n,1]) #那么在列表b中添加改行为新的一项
f2=file("2.txt", "w") #打开2.txt文件,用于输出
for n in b: #输出格式为:行信息 (tab) 出现次数 (回车)
f2.write(str(n[0][0:-1]) + "\t")
f2.write(str(n[1]) + "\n")
f2.close
print "Finished" #完成
使用open函数逐行读取文件,依次对比,如包含要求字符串,则数量累加1,读取完成后可统计出行数,代码如下:
n = 0for line in open('filename','r'):
if '固定字符串' in line:
n += 1
print(n)
说明:
使用 for line in open这种方式可以提高代码效率,如需要更复杂统计,例如重复行,则可以使用hash函数,把行hash值存入列表,再做统计。