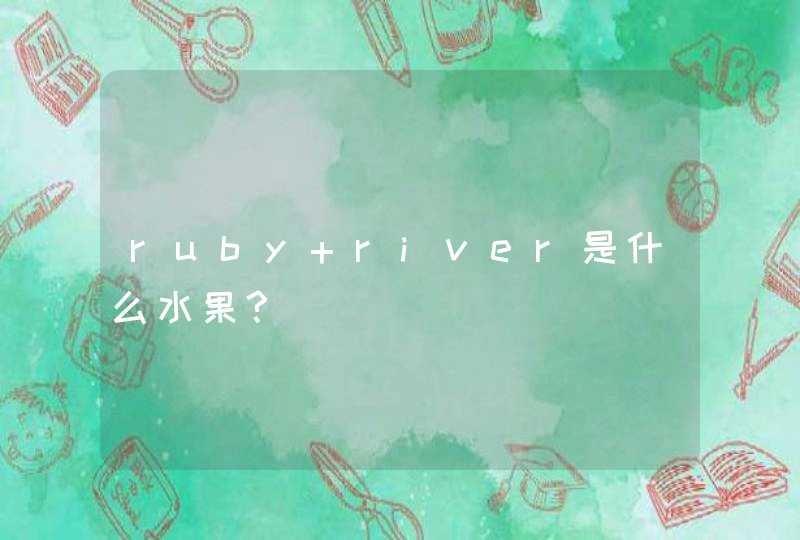如data.frame为:zz, 绘图如下:
a. single protein:线性回归画法
1. ggplot(zz,aes(x=a, y=HDL))+
geom_point(alpha=1,colour="#FFA54F")+
geom_smooth(method = lm,colour="#8B658B")+
#scale_color_brewer(palette = "Set1")+
theme_bw()+
labs(x="Ferritin",y="HDL.C",title="Pearson’s correlation test of ferritin and HDL.C")+
annotate("text", x = 1000, y = 2.5, label = "r = -0.51",colour="black",size=4)
2. library(ggstatsplot)
ggscatterstats(data = alldata,
y = TRANSFUSION.UNIT,
x = NPTXR,
centrality.para = "mean", #"mean" or "median"
margins = "both",
xfill = "#D8BFD8",
yfill = "#EEDD82",
#line.size= ,
line.color="#8B6969",
point.color="#2F4F4F",
marginal.size=4,
marginal.type = "density", # "histogram", "boxplot", "density", "violin", "densigram")
title = "Relationship between TRANSFUSION.UNIT and NPTXR")
b. ggcorrplot, 全部蛋白 global correlation map 画法
ggcorrplot(cor(alldata))
2. summary(lm(y~x),method=" ") %>%.[["coefficients"]] 正规线性回归
(其实就是:a<-lm(y~x1+x2+...,data)
plot(summary(lm(y~x),method=" ")) #绘图
3. ggcor部分数据绘图: 数据类型为data.frame,纵坐标为各指标or各蛋白,行为观测值。
data <- fortify_cor(alldata[,10:11],alldata,cluster.type = "col")
ggcor<-ggcor(data,label_size=0.5) +
geom_colour()+
theme(axis.text.x = element_text(colour = "black",size = 4.7),
axis.text.y=element_text(size=5.5),
axis.ticks=element_blank())+
geom_num(aes(num=r),colour="black",size=1.5)
4. corrr包画法
datasets::mtcars %>%
correlate() %>%
focus(-cyl, -vs, mirror = TRUE) %>%
rearrange() %>%
network_plot(min_cor = .2)
>>> data1 <- data7_0 %>%group_by(CELLPHONE,MEMBERID) %>% filter(row_number() == 1) %>% ungroup()1234
方法二:
>>> data2 <- data7_0 %>%
distinct(CELLPHONE,MEMBERID, .keep_all = TRUE)12
方法三:
>>> data3 <- sqldf("select DISTINCT CELLPHONE,MEMBERID from data7_0")1
方法四:
>>> data4 <- base::unique(data7_0)1
方法五:
>>> data5 <- as.data.table(data7_0[!duplicated(data7_0$CELLPHONE), ])
可以利用as.factor 函数,将该列转换为factor数据类型,在使用summary来看数据信息:如列表命名为 raw.data
summary(as.factor(raw.data$subject))
就可以了。举一个列子:
a<-c("a","a","b","c")
summary(as.factor(a))