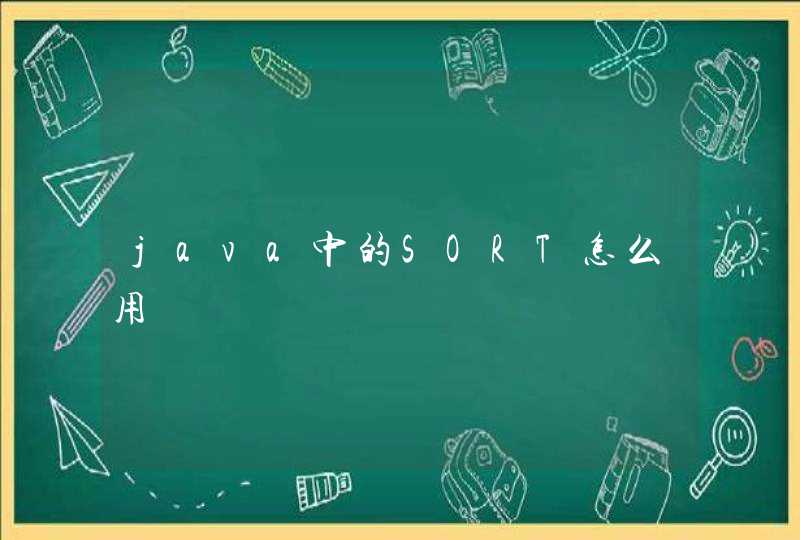formula代表拟合的公式,如Y~X,则对因变量Y和自变量X作线性拟合拟合模型为 y=a+bx ,如Y 0+X或Y X+0则除对因变量Y和自变量X作线性拟合外,还规定改直线必过原点及拟合模型为 y=x 。
lm对象即lm函数返回的值,其属性包括
常用的有 coefficients , residuals 和 fitted.values ,分别表示拟合的得到的各系数的值、残差和预测值。
可以看出该拟合曲线为y=0.52805925 -0.02797779x
其他值的调用,包括p值,给定x预测的y值,拟合系数R方等需要通过summary函数调用
也可以直接通过 summary(line.model) 打印出大部分与回归直线相关的一些结果
曲线拟合:(线性回归方法:lm)1、x排序
2、求线性回归方程并赋予一个新变量
z=lm(y~x+I(x^2)+...)
3、plot(x,y)#做y对x的散点图
4、lines(x,fitted(z))#添加拟合值对x的散点图并连线
曲线拟合:(nls)
lm是将曲线直线化再做回归,nls是直接拟合曲线。
需要三个条件:曲线方程、数据位置、系数的估计值。
如果曲线方程比较复杂,可以先命名一个自定义函数。
例:
f=function(x1, x2, a, b) {a+x1+x2^b}
result=nls(x$y~f(x$x1, x$x2, a, b), data=x, start=list(a=1, b=2))
#x可以是数据框或列表,但不能是矩阵
#对系数的估计要尽量接近真实值,如果相差太远会报错:“奇异梯度”
summary(result) #结果包含对系数的估计和p值
根据估计的系数直接在散点图上使用lines加曲线即可。
曲线拟合:(局部回归)
lowess(x, y=NULL, f = 2/3, iter = 3)
#可以只包含x,也可使用x、y两个变量
#f为窗宽参数,越大越平滑
#iter为迭代次数,越大计算越慢
loess(y~x, data, span=0.75, degree=2)
#data为包含x、y的数据集;span为窗宽参数
#degree默认为二次回归
#该方法计算1000个数据点约占10M内存
举例:
x=seq(0, 10, 0.1)y=sin(x)+rnorm(101)#x的值必须排序
plot(x,y) #做散点图
lines(lowess(x,y)) #利用lowess做回归曲线
lines(x,predict(loess(y~x))) #利用loess做回归曲线,predict是取回归预测值
z=loess(y~x)lines(x, z$fit) #利用loess做回归曲线的另一种做法
nls的数据源必须有误差。不能精确等于公式返回值(零残差)。循环次数大于50通常是使用 函数精确返回值 作为数据源去拟合函数。必须给y值加上随机误差。
z=function(x,a,b){a*sin(x)+b*cos(x)}x=seq(1,10,9/500)
y=z(x,1,1) # a=1 b=1 是期望拟合出的结果。
cor=data.frame(x=x,y=y)
cor$res=runif(length(cor$x),min=-0.005,max=0.005)
cor$yres=cor$y+cor$res
#yres =y加上随机误差,y是精确返回值
> nls(cor$yres~z(cor$x,a,b),data=cor,start=list(a=0.8,b=1.3))
Nonlinear regression model
model: cor$yres ~ z(cor$x, a, b)
data: cor
a b
0.9999 1.0002
residual sum-of-squares: 0.004213
Number of iterations to convergence: 1
Achieved convergence tolerance: 2.554e-07
#使用精确返回值拟合就会出错。
> nls(cor$y~z(cor$x,a,b),data=cor,start=list(a=1,b=1))
Error in nls(cor$y ~ z(cor$x, a, b), data = cor, start = list(a = 1, b = 1)) :
循环次数超过了50这个最大值