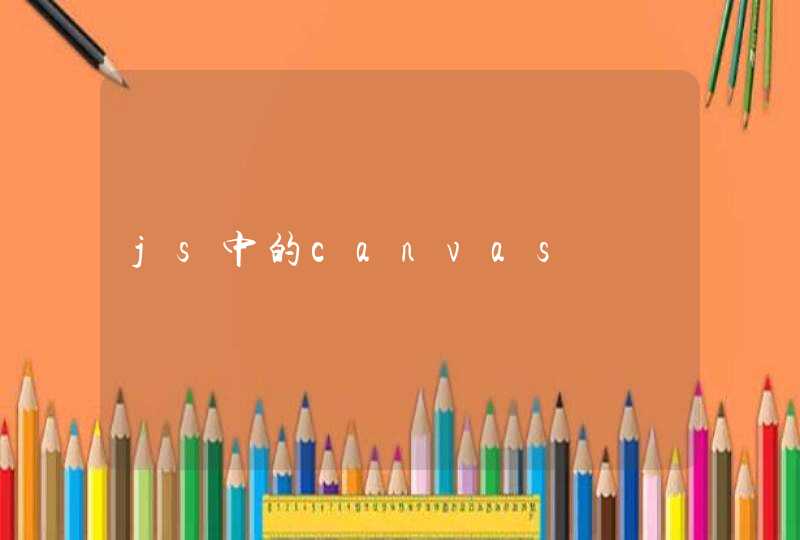S=svd(A)表示对矩阵A进行SVD分解,分解的结果是得到3个矩阵,如果返回值只有一个,那么可以得到A的奇异值向量。
eig(A)表示求矩阵A的特征值。
所以区别就是,svd得到的是A的奇异值,eig得到的是A的特征值。
A'表示A的转置矩阵,A'*A的n个非负特征值的平方根叫作矩阵A的奇异值。记为σi(A)。
希望可以帮助你,望采纳!
如果不同特征的数量级不在一个等级,模型就不是碗形,而是长条形,难收敛。如果是逻辑回归、线性回归,一定要做幅度调整,如果用树模型,就不需要幅度调整。因为树模型是对各个特征一个一个做的,幅度差异不影响。
可以把不同特征调整到[0,1]范围内,(x-min)/(max-min),适用于非高斯分布,可以保留数值大部分信息,但易受到异常值影响。
或者使用standard scaler, ,适用于高斯分布。优点是处理后的数据更加正态化,但是缺点是对分布要求严格。
树模型(决策树、随机森林、GBDT)不需要做数值的缩放,线性模型、SVM、神经网络、KNN、PCA降维都是需要做数值缩放的。
1)加减平均:商品价格高于平均价格多少,用户在某个品类下消费超过平均用户多少,用户连续登录天数超过平均多少。。。
2)分位线:商品属于售出商品价格的多少分位线处。
3)次序型:排在第几位
4)比例类:电商中,好/中/差评 比例,你已超过全国百分之多少的同学。
比如年龄,是一个连续值。如果要通过逻辑回归来判断是否要让座,要同时顾及“尊老”“爱幼”。而激活函数sigmoid函数是 ,如果 是正数,函数是单调增,年龄越大让座可能越大,但是小孩子就不让座了,如果 是负数,函数单调减,只能满足爱幼,不能尊老了。所以,将年龄字段分成[0,6],[7,59],[60,120]三段,变成三个字段,对应就会有三个 来判别,是否应该让座,就可以同时实现尊老和爱幼。
1)等距切分。pd.cut()
2)等频切分,按照分位数切分。pd.qcut()
如果是用逻辑回归模型,就要做离散化,如果使用树模型,如决策树、随机森林,就不一定要做离散化,因为模型本身会给你做离散化。
口红色号,衣服尺码等等
red:--->1
blue:--->2
yellow:--->3
如果用以上的编码方式,不同颜色之间存在了大小关系,而应该是等价的。
red:-->1,0,0
blue:-->0,1,0
yellow:-->0,0,1
拆分成三列,“是否是red”、"是否是blue"、“是否是yellow”。
操作:pd.get_dummies()
哑变量和one hot其实是一件事,就像奇异果和猕猴桃。
相当于multi-hot,有多个1。
比如,我可以建一个词库,一句话里如果含有单词apple,那就在apple这列打1,含有多少单词就打多少个1。但是这种方法比较稀疏,词库太大了。
改进方法:比如我对于每一个领域都有一个词表,比如财经类词表,体育类词表。。。然后有一篇文章,我要对他进行分类,就可以看这篇文章里有多少个词是财经词表里的,有多少词是体育词表里面的。
比如:
性别:[男,女]
爱好:[足球,散步,电视剧]
要用爱好来表达性别
男生中这三个爱好的人数比例是:[2/3, 1/3, 0]
女生中这三个爱好的人数比例是:[0, 1/3, 2/3]
把这三列 [“喜欢足球的概率”,“喜欢散步的概率”,“喜欢电视剧的概率”] 加在对应的性别后面,可以作为新的特征。
4.如果类别特征空间太大,超过了几十个一般就不适用one hot了。比如是中介的ID,可以考虑用Label encoding(直接用1,2,3代替,会产生次序关系,但总好过直接丢弃特征)、Count encoding(出现了多少次就写多少)、Target encoding(根据标签,反过来对特征编码,使用方法就是上面的histogram,但是会造成标签泄露,产生过拟合。可以用交叉验证的思想,分成5折,用4份的数据做编码,然后用剩下的一份做训练。)
既可以作为连续值,也可以作为离散值。
连续值:持续时间(浏览时长)、间隔时间(上次购买距离现在的时间)
离散值:哪个时间段、周几 等,离散后,就是类别型的数据。但不是说一定要做one-hot编码,比如时间段,可以离散化为“上班高峰期”和“非高峰期”。而周几,可以用one-hot,也可以离散为“工作日”和“周末”。
1、词袋模型:就是指上面的hash技巧,文本数据去掉停用词,剩下的词组成list,在词库中的映射稀疏向量。
2、词袋模型的问题: 李雷喜欢韩梅梅 VS 韩梅梅喜欢李雷,丢失了顺序信息。
解决方案:把词袋中的词扩充到n-gram,就是分词的时候,除了“李雷”、“喜欢”、“韩梅梅”,还要加上“李雷喜欢”、“喜欢韩梅梅”。这叫2-gram。在python里的库叫CountVectorizer。
3、新的问题:只统计了频次,但是,出现频次高的一定是重要的吗?
解决方案:使用TF-IDF特征。如果t虽然在文档中出现次数多,但是在其他文档中出现的次数也很多,那么这个词就不重要。
TF(t)=
IDF(t)=
TF-IDF权重=TF(t)*IDF(t)
4、稀疏-->稠密,工具是word2vec,在机器学习中不太好用,在深度学习中用得多。原理比较复杂,先不讲。
比如:
1)购物车购买转化率(用户维度统计特征)
2)商品热度(商品维度统计特征)
3)对不同item点击/收藏/购物车/购买的总计(商品维度统计特征)
4)对不同item点击/收藏/购物车/购买平均每个user的计数(用户维度统计特征)
5)变热门的品牌/商品(商品维度,差值型)
6)最近1/2/3/7天的行为数与平均行为数的比值(用户维度,比例型)
7)商品在类别中的排序(商品维度,次序型)
8)商品交互的总人数(商品维度,求和型)
等等。。。
统计值也可以用来发现一些规律,比如前一天加购物车的商品很有可能第二天购买;加车N件,只买了一件,剩余的不会买。。。
如:张三&&电子产品,李四&&服装,
增加一列,只有同时出现指定的用户和品类的时候,才取1。
第一种组合完全是拍脑袋,所以可以结合使用 决策树模型 (GBDT),用GBDT学习出来的路径,组合成新的特征。不一定是整条路径,选取其中的一小段也可以是一个新的特征。例如下图,“年龄 25 &&是教师” 就是一个新的特征。
1)冗余,部分特征相关度高,消耗计算性能。
2)噪声,有些特征对结果有负影响。
前者只踢掉原本特征里,和结果预测关系不大的列。后者是要在低维空间中,尽量保存住高维的信息。
1)评估 单个 特征和结果值之间的相关程度,排序,留下Top相关的特征部分。
2)Pearson相关系数,
3)缺点:没有考虑到特征之间的关联作用,可能把有用的关联特征误踢掉。
python包:SelectKBest(选最重要的K个)、SelectPercentile(选最重要的百分之多少)
看做一个子集搜索问题,筛选各种特征子集,用模型评估效果。
典型的包裹型算法为:递归特征删除算法(recursive feature elimination algorithm)。
做法:
1)先用全量特征跑逻辑回归模型
2)然后系数排序(体现相关性),砍掉5-10%的弱特征,观察准确率/auc的变化。
3)逐步进行,直至准确率/auc出现大的下滑为止。
python包:RFE
L1正则化 + 逻辑回归LR/ linear SVM
L1正则化的效果,是让一些不重要的特征的权重系数变成0。
通常用在 稀疏的高维 数据。
奇异值分解(svd) 是线性代数中一种重要的矩阵分解在Python的numpy包里面直接调用
其中,u和v是都是标准正交基,问题是v得到的结果到底是转置之后的呢,还是没有转置的呢,其实这个也很好验证,只要再把u,s,v在乘起来,如果结果还是A 那么就是转置之后的,结果确实是这样的,但是MATLAB却与之不同,得到的v是没有转置过的
奇异值分解可以被用来计算矩阵的 伪逆 。若矩阵 M 的奇异值分解为